|
|
| Groklaw's Proposed Response to the USPTO's Request for Suggested Topics for Future Discussion - Care to Help? ~pj |
 |
|
Sunday, March 10 2013 @ 08:43 PM EDT
|
Here's Groklaw's proposed response to the USPTO's request for suggested topics for discussion in the future by the Software Partnership, as it calls it. Thank you for your input, everyone. But please take a look at the result. We tried to incorporate everything that would strengthen the draft. This was a group project by the membership at Groklaw, and now we'd appreciate feedback from the world, before we send it off on Friday.
We came up with four topics for future discussion. You may think of others. Because we have to file this on Friday, and that means if you want to contribute a thought, please do it by Wednesday. We are also publishing a more detailed supplement on those four topics, explaining in depth why we propose those four topics, providing some foundation and providing resources. This we will not sent to the USPTO, but it is referenced in the document we will send, if they wish to read more. If you think my decision on that is flawed, let me know. But all they asked for is topics. If we overwhelm them with a lot of what they didn't ask for, I worry that it would be counterproductive. The USPTO will be publishing the comments they receive, and so both documents will be available to the world, and people can read it or not based on their interest level, which is part of the purpose. I would particularly appreciate your help with the supplement.
Jump To Comments
[Suggested Topics ]
[The Supplement]
First, here's the document we will send to the USPTO, the list of the four proposed topics for discussions, after which you'll find the supplement. Feel free to comment on either document:
Response to the USPTO on the Second Topic:
Suggested Additional Topics for Future Discussion by the Software Partnership
In response to the USPTO's request for topics for future discussion by the Software Partnership, the technical community at Groklaw suggests the following four topics, in order of priority:
1: Is computer software properly patentable subject matter?
2: Are software patents helping or hurting innovation and
the US economy?
3: How can software developers help the USPTO
understand how computers actually work, so issued patents
match technical realities, avoiding patents on functions that
are obvious to those skilled in the art, as well as avoiding duplication of prior art?
4: What is an abstract idea in software and how do *expressions* of
ideas differ from *applications* of ideas?
In order to explain why these topics could be fruitful, here are some brief thoughts in explanation.
Suggested topic 1:
Is computer software properly patentable subject matter?
If software consists of two elements neither of which is patentable subject matter,
can software itself by patentable subject matter? Software consists of algorithms,
in other words mathematics, and data, which is being manipulated by the algorithms. Mathematics
is not patentable
subject matter and neither is data. On what basis, then,
is software patentable subject matter? We would welcome a
discussion on this topic, as it is a key issue to the developer community. Note
that Groklaw has published a number of articles on this topic, which can be found
at http://www.groklaw.net/staticpages/index.php?page=Patents2
A particular point of interest is how the meaning of data influences the patentable
subject matter analysis. Computers manipulate bits, and bits are electronic symbols
which are used to convey meaning. In some patents, like in Diehr's
industrial process
for curing rubber, what this meaning signifies is actually claimed clearly.
But in most pure
software patents the meaning is merely referred to. Should this distinction influence
whether the claim is patentable?
Suggested topic 2:
Are software patents helping or hurting the US innovation and
hence the economy?
It would be useful to hear from entrepreneurs on a wide scale on the effects software
patents are having on their startups or business projects. Microsoft's Bill Gates
himself has stated
that if software patents had been allowed when he was starting his business, he would have
been blocked.1a Is that happening to today's entrepreneurs? If
software authors are unable to clear
all rights to their own products because there is no practical way to do
so, how can that foster progress and innovation? Rather it seems to force
developer, or the companies that hire them, to
choose between developing innovative products with the certainty that if it is successful,
there will be
infringement lawsuits, or stop developing.
Every firm with an internal IT
department writes software. Every firm which maintains it own website writes
software. There are roughly 634,000 firms in the United States with 20 or more
employees. While not all of these firms produce software, many of the 1.7 million
firms with 5 to 19 employees do. In an ideal world, all firms should verify all
patents as they are issued to avoid infringement. This is a constant on-going
activity because corporate software must frequently be adapted to new needs and all
new versions may potentially infringe a patent. A study has concluded the task is
mathematically impossible to
accomplish.2a
Even if a patent lawyer only needed to look at a patent for 10 minutes, on average,
to determine whether any part of a particular firm's software infringed it, it would
require roughly 2 million patent attorneys, working full-time, to compare every
firm's products with every patent issued in a given year.
This is a mathematical impossibility because there are only roughly 40,000 registered
patent attorneys and patent agents in the US.
This estimation covers just the work of keeping up with the newly issued patents
every year. Checking already issued patents would require more attorneys.
This result follows from simple arithmetic. Suppose we assume that
40,000 patents are issued
per year, 600,000 firms actively write software, resulting in
approximately 2000 billable
hours per attorney per year. Then the math is straightforward: 40,000 patents*600,000
firms*(10 minutes per patent-firm pair)/(2000*60 minutes per attorney)=2 million
attorneys.
Compare lines of
code with sentences in a book. Each English sentence expresses an idea. Each
combination of sentences expresses a more complex idea. Then more and more complex
ideas are expressed into paragraphs, chapters etc. The total number of ideas from all
works of authorship is extremely large. Imagine an hypothetical intellectual property
regime where all such ideas are patentable. This would generate a large number of
patents. All authors must check all patents
for potential infringement. It simply is not possible to do so.
It is impossible to promote innovation with a system where the authors of software
have no way to verify they own all rights to their own work. Such a system is
guaranteed to harm the economy with monopolistic rent-seeking and unneeded
litigation.
Suggested topic 3:
How can software developers help the USPTO
understand how computers actually work, so issued patents
match technical realities, avoiding patents on functions that
are obvious to those skilled in the art, as well as avoiding duplication of prior art?
The current interpretation of patent law is plagued with what developers view as
erroneous conceptions of how computers work. Other than the current USPTO request for
input, developers feel shut out of decisions, and yet they are the very ones who
understand what software is and how it does what it does.
Textbooks describe in detail what mathematical algorithms are, but no one seems to
understand or to reference these sources. Instead, we see courts using
standard dictionaries, and the
result is confusion about what algorithms are. An unrealistic distinction between
so-called mathematical algorithms and those that purportedly are not mathematical has
been the result. Since this impacts the controversy of when a computer-implemented
invention is directed to a patent-ineligible abstract idea, it's a serious omission.
Second, it seems some, including some courts, believe the functions of software
are performed through
the physical properties of electrical circuits,
incorrectly treating the computer as a device which operates solely through the laws of
physics. This approach is factually and technically incorrect
because not everything in software
functions through the laws of physics. Bits are symbols, and they have meanings. The
meaning of bits is essential to performing the functions of software. The capability
of bits to convey meaning is not a physical property of the computer.
Software developers don't write software by working with the physical properties of
circuits. Developers define the meaning of data and implement operations of
arithmetic and logic that apply to the meaning. They debug software by reading the
meaning of the data stored in the computer and verifying whether the correct
operations are performed. The aspects of software related to meaning cannot be
explained solely in terms of the physical properties of the computer.
This erroneous physical view of the computer is the basis of an oft-stated
argument. Some claim that software alters the computer it runs on. This is used to
justify the view that software patents are actually a subcategory of hardware
patents. But to demonstrate what is wrong with that argument, let's compare a
printing press with a computer.
It is easy to see that the contents of a book is not a machine part. The meaning of a
book is not explained by the laws of physics applicable to a printing press. But the
comparison with a computer shows that there is no material difference in their
handling of meaning. Any argument applicable to a printing press is applicable to a
computer and vice-versa.
Imagine a claim on a printing press configured to print a specific book, say
Tolkien's Lord of the Ring. This is a claim on a machine which operates according to
the laws of physics. Printing is a physical process for laying ink on paper. It
functions without the intervention of a human mind. But still this process involves
the meaning of a book. The claim is infringed only if the book has the recited
meaning.
We may argue that a configured printing press is physically different from an
unconfigured one. The configured printing press can print a book while the
unconfigured one cannot. Books with different contents are different articles of
manufacture. Differently configured printing presses perform different functions
because they make different articles of manufacture. Therefore, as this hypothetical
argument goes, a printing press configured to print a specific book is a specific
machine which performs a specific practical and useful task.
Software patents are often written similarly to this analogy. Like a printing
press, the computer operates according to the laws of physics. It functions mostly
without the intervention of the human mind, although from time to time human input
may be required. But the process of computing needs the meaning of the data to
actually solve problems. The claim is infringed only if the data has the recited
meaning.
The standard argument that a programmed computer is different from an unprogrammed
one is exactly symmetric to the one we have just made about printing presses. There
is a reason for this. The technologies are not that different. A computer connected
to a printer can be configured to print a book. Also modern printing presses may be
controlled by embedded computers.
There is no material difference between a configured printing press and a programmed
computer in their handling of meaning. Users of a computer read the meaning of
outputs. They also enter the inputs based on the meaning. When programming a
computer, programmers must define the meaning of data. They implement algorithms
which perform operations of arithmetic and logic on the meaning of this data. When
debugging, programmers must inspect the internals of the computer to determine
whether the correct operations are being performed. This requires reading the
contents of computer memory and verifying it has the expected meaning. In other
words,
the act of making the invention depends on defining and reading the data stored in
the computer. Software works only if the data has the correct meaning.
The output of a printing process is a book. Different books are distinguished by
their contents. A typographer must define and verify the contents of the information
to be printed to configure the printing press correctly. In other words, the act of
making the invention depends on defining and reading the data stored in the printing
press. A printing press works precisely because it prints the right contents.
Printing makes a physical book which can be read and sold. Books with different
contents are different books. A wrongly configured printing press prints the wrong
book. Therefore the utility of the printing press doesn't depend just on the laws of
physics. It also depends on the contents of the book.
Both machines work in part according to the laws of physics and in part through
operations of meaning.
The courts have failed to acknowledge the role of meaning in software.
Some errors result from the failure to take into
consideration the descriptions of what is a mathematical algorithm in mathematical
literature. Other errors result from explicitly and incorrectly denying the role of
symbols and meaning in computers. And more errors result from the belief that
computers operate solely through the physical properties of electrical circuits.
Imagine now that every time a printing press prints a new book, you could patent that
printing press as a new machine because it printed a new book. That is exactly what
patent law does with software, purporting to create a new machine because new
software running on the computer supposedly creates a new machine. And yet the
computer, like a printing press, can run any software at all that you can devise,
just as a printing press can print any book you write.
No one
would allow a patent on a previously existing printing press just because it is now
configured to print a new novel. Yet that is exactly what is allowed with software.
The consequence is a proliferation of patents on the expressions of ideas.
Suggested topic 4:
What is an abstract idea in software and how do expressions of
ideas differ from applications of ideas?
Abstract is not synonymous with vague or overly broad. A mathematical algorithm is
narrowly defined with great precision, but still it is abstract.
Abstract is not the opposite of useful. The ordinary procedure for carrying an
addition is a mathematical algorithm. It has a lot of practical uses in accounting,
engineering and other disciplines. But still it is abstract. In particular it is
designed to handle numbers arbitrarily large no matter whether we have the practical
means of writing down all the digits. Besides, there are useful abstract ideas
outside of mathematics. For example the contents of a reference manual such as a
dictionary is both abstract and useful.
Mathematics is abstract in part because it studies infinite structures.
For example,
the series of natural numbers 0, 1, 2, ... cannot exist in the concrete universe,
because it is infinite. Also, symbols in a mathematical sense are abstract entities
distinct from the marks on paper or their electronic equivalent. For example, there
are infinitely many decimals of pi even though there is no practical way to write
them down. Infinity guarantees that mathematics is abstract. Therefore a definition
of "abstract ideas" must
acknowledge the abstractness of mathematics.
A proper
understanding of the role of meaning is key to understanding when a claim is directed
to a patent-ineligible abstract idea in software.
Software patents don't claim abstract ideas directly. They claim them indirectly
through the use of a physical device to represent them by means of bits. It would be
easier to recognize claims on patent-ineligible abstract ideas if it were understood
they take the form of claims on expressions of ideas as opposed to
applications of
ideas. The bits are symbols and the computation is a manipulation of the symbols.
Expressions of ideas occur through this use of symbols.
This suggests a test similar to the printed matter doctrine. This test is best
described using the concepts and vocabulary of a social science called semiotics.
This science studies signs, entities which are used to stand for something else.
Computers should be recognized to be what semioticians call sign-vehicles, physical
devices which are used to represent signs. The sign itself is an abstraction
represented by the sign-vehicle. Hence, sign-vehicles and signs are distinct
entities.
In semiotics the triadic notion of a sign distinguishes between two types of meaning.
There is the actual worldly thing denoted by the sign. This is called the referent.
And there is the idea of that thing a human being would derive from reading the sign.
This is called an interpretant. A sign usually conveys both types of meanings
simultaneously. An example might be a painting representing a pipe. The painting itself
is a sign-vehicle. People seeing this painting will think of a pipe. This thought is
an interpretant. An actual pipe is a referent.
If nothing has been invented but thoughts in the mind of human beings, we should not
be able to claim a sign-vehicle expressing these ideas as if they were applications
of the ideas. But when the real thing denoted by the expression is claimed, we may
have a patentable invention. For example a mathematical calculation for curing rubber
standing alone is not patentable under this test. It is just numbers letting a human
think about how rubber should be cured. But when the actual rubber is cured the
referent is recited and the overall process taken as a whole may be patentable. These
ideas lead to this test.
A claim is directed to a patent-ineligible abstract idea when there is no nonobvious
advances over the prior art outside of the interpretants. A claim is written to an
application of the idea when the referent is claimed instead of merely referred to.
This test is technology-neutral. It is applicable precisely when the claimed
invention is a sign, or when it is a machine or process for making a sign. It applies
whether the invention is software, hardware or some yet to be invented technology.
This test works without having to define the boundary between what is software and
what isn't.
The concepts of semiotics are quite simple and easy to define. They are related to
the dichotomy between ideas and expression of ideas in copyright law. Therefore this
test for abstract ideas helps clarify the line between what should be protected with
copyrights and what belongs to patent law. The expressions of interpretants may be
protected by copyrights and the corresponding referents may be protected by patents.
This test will correctly identify abstract mathematical ideas. Mathematics is, among
other things, a written language. It has a syntax and a meaning which are defined in
textbooks on topics such as mathematical logic. Algorithms in the mathematical sense
are features of this language. They are procedures for manipulating symbols. They
solve problems because they implement operations of arithmetic and logic on the
meaning of the symbols. Algorithms are also procedures which are suitable for machine
implementation. Computer programs may solve a problem only if it is amenable to an
algorithmic solution. In this sense, all software executes a mathematical algorithm.
Mathematical language refers to abstract mathematical entities such as numbers,
geometric shapes, etc. We assimilate this abstract meaning with interpretants.
Mathematical language may also be used to describe things in the concrete world, for
instance using laws of physics. The corresponding referents are applications of
mathematics. Mathematical algorithms and other types of mathematical subject matter
are a subcategory of interpretants. And things in the concrete world modeled using
mathematical language are a subcategory of referents. Hence the proposed test will
properly distinguish between the expression of a mathematical idea from an
application of the same idea. Claims of applications are accepted while claims on
expressions are rejected.
Groklaw has published this document here, along with a more detailed explanation, with references,
on why we believe these four topics could be fruitful topics for discussion.
__________
1a Gates exact words were:
"If people had understood how patents would be granted when most of today's ideas were
invented, and had taken out patents, the industry would be at a complete standstill
today."
"Challenges and Strategy" (16 May 1991).
Also from: http://bat8.inria.fr/~lang/reperes/
local/Challenges.and.Strategy
2a See Mulligan, Christina and Lee, Timothy B., Scaling the Patent System (March 6,
2012). NYU Annual Survey of American Law, Forthcoming. Available at SSRN:
http://ssrn.com/abstract_id=2016968.
The quoted paragraph is at pages 16-17.
And here is the more detailed explanation, the supplement. And this is where I really need your help. I didn't write it, although I've tried to organize it, but I'm still editing it to try to make it a little more conversational, so if you see errors or shades of meaning that are slightly off, please say so:
Supplement to the Response to the USPTO on the Second Topic
Detailed Explanations on the Proposed Topics
by Groklaw
The patent system should distinguish the expression of an abstract idea from an application of an idea. Currently the distinction between the two is not correctly made in the legal analysis of software patents. Expressions of ideas are being mistaken for applications and are patented as a result. This makes it confusing to try to define what is a claim directed to patent-ineligible abstract ideas.
Because of this confusion, innovation is not being promoted as intended. When expressions of ideas are patented, none of the assumptions underlying the operating principles of the patent system are true. Therefore the expected benefits of patents are not realized.
Recognizing that an expression is not an application would make it possible for the patent system to be able to recognize claims directed to abstract ideas and a major source of problems with software patents would be corrected.
A. Factual Background
Let's begin by defining some important terms and summarizing some fundamental facts about computers, software, and the underlying mathematical principles.1
1. Semiotics defines the concepts and vocabulary necessary to understand issues of meaning.
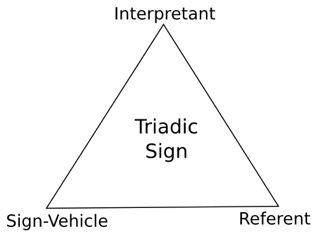
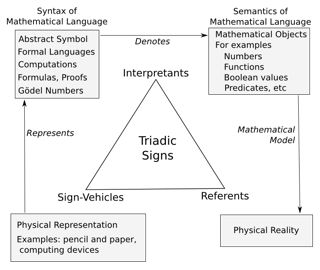
In the social science of semiotics, a thing that stands for something else is called a sign. Books and computers when associated with their meanings are examples of signs. Semiotics defines the concepts and vocabulary we need to properly analyze meaning. We present here the basic concepts which will be used in the rest of this response.
A sign in the Piercean tradition has three elements. The physical object used to represent the sign is called a sign-vehicle. The entity in the world which is denoted by the sign is called the referent. The idea a human being would form of the meaning of the sign is called an interpretant. This triadic view of a sign is traditionally represented as a triangle.
We may use the famous painting The Treachery of Images as an illustration of these notions. This painting represents a pipe with the legend "Ceci n'est pas une pipe" which means "This is not a pipe" in French. The point is that a painting of a pipe is a representation of a pipe. It is not the pipe itself. In this example, the painting is the sign-vehicle, the actual pipe is the referent, and the idea of a pipe in the human mind is the interpretant.
We have a sign when there is a convention on how to associate the sign-vehicle with its meaning. In the case of the painting this convention is the practice of associating a visual representation of something with what is represented.
Please note how the sign-vehicle is only an element of a sign. It is not the whole sign. The three elements must be brought together in order to have a sign. A human interpreter with the knowledge of the convention will mentally assemble the three elements and "make the sign" by associating the sign-vehicle with its meaning. This is a cognitive process of the human mind called
semiosis. In particular, books and computers when taken as physical objects independently of their meanings are sign-vehicles. They are not the whole signs because semantical elements are not physical parts of books and computers. These sign-vehicles are turned into signs by semiosis when a human interpreter read meanings into them.
2. Mathematics is a written language based on logic and algorithms are procedures for manipulating symbols in this language.
Mathematics is a written language. We can find the definition of its syntax and semantics in textbooks on the foundations of mathematics, especially mathematical logic.2 There is more to mathematics than the language. Mathematical entities like numbers and geometrical figures are also mathematics. But for the purpose of this discussion it is the linguistic aspect that matters most.
Concepts such as formulas, equations and algorithms are part of this mathematical language.
A mathematical formula is text written with symbols in this mathematical language. It is the equivalent of a sentence in English. An equation is a special kind of formula which asserts that two mathematical expressions refer to the same value.
The famous equation E=mc2 is an example of such a mathematical formula. The meaning of this formula is a is a law of nature, actually a law of physics. It is a statement relating the mass of an object at rest with how much energy there is in this object. This shows how mathematical language may be used to describe the real world.
The formula implies a procedure to compute the energy when the mass is known. Here it is:
-
Multiply the speed of light c by itself to obtain its square c2.
-
Multiply the mass m by the value of c2 obtained in step 1.
-
The result of step 2 is the energy E.
This kind of procedure is known in mathematics as an algorithm. The formula is not the algorithm. This procedure is the algorithm. Someone with sufficient skills in mathematics will know the algorithm simply by looking at the formula. This is why it is often sufficient to state a formula when we want to state an algorithm.
The task of carrying out the algorithm is called a computation. When carrying out the algorithm with pencil and paper we have to write mathematical symbols, mostly digits representing numbers but also other symbols such as the decimal point. These writings too are parts of mathematical language. In the example, the meaning of the writings are numbers representing the speed of light, its square, the mass and the energy of an object.
A function is not an algorithm.
Mathematicians distinguish between a function and an algorithm. Hartley Rogers explains:3 (emphasis in the original)
It is, of course, important to distinguish between the notion of algorithm, i.e., procedure, and the notion of function computable by algorithm, i.e., mapping yielded by procedure. The same function may have several different algorithms.
A mathematical function is a correspondence between one or more input values and a corresponding output value. For example the function of doubling a number associates 1 with 2, 2 with 4, 3 with 6 etc. Nonnumerical functions also exists.
A function is not a process. There is no requirement that the function must be computed in a specific manner. All methods of computation which produce the same output from the same input compute the same function.
Despite the similarly sounding words, a software function is not the same thing as a mathematical function. However the two concepts are closely related. If we look at the underlying principles of mathematics which are at the foundations of computer science the functions of software are described with mathematical functions.4 The methods used to perform the functions of software are implemented using mathematical algorithms.
The language of mathematics is based on logic
There is a close connection between logic and mathematics. Theorems are proven by means of deductions where the formulas and expressions in mathematical language are organized according to the rules of logic. Most mathematical truth are established in this manner.
The relationship between mathematics and logic is explained by Haskell Curry as follows:5 (emphasis in the original, footnote omitted)
The first sense is that intended when we say that "logic is the analysis and criticism of thought." We observe that we reason, in the sense that we draw conclusions from our data; that sometimes these conclusions are correct, sometimes not; and that sometimes these errors are explained by the fact that some of our data were mistaken, but not always; and gradually we become aware that reasonings conducted according to certain norms can be depended on if the data are correct. The study of these norms, or principles of valid reasoning, has always been regarded as a branch of philosophy. In order to distinguish logic in this sense from other senses introduced later, we shall call it philosophical logic.
In the study of philosophical logic it has been found fruitful to use mathematical methods, i.e., to construct mathematical systems having some connection therewith. What such system is, and the nature of the connection, are question which will concern us later. The systems so created are naturally a proper subject for study in themselves, and it is customary to apply the term 'logic' to such a study. Logic in this sense is a branch of mathematics. To distinguish it from other senses, it will be called mathematical logic.
…
[A]lthough the distinction between the different senses of 'logic' has been stressed here as a means of clarifying our thinking, it would be a mistake to suppose that philosophical and mathematical logic are completely separate subjects. Actually, there is unity between them. mathematical logic, as has been said, is fruitful as a means of studying philosophical logic. Any sharp line between the two aspects would be arbitrary.
Finally, mathematical logic has a peculiar relation to the rest of mathematics. For mathematics is a deductive science, at least in the sense that a concept of rigorous proof is fundamental to all parts of it. The question of what constitutes a rigorous proof is a logical question in the sense of the preceding discussion. The question therefore falls within the province of logic; since it is relevant to mathematics, it is expedient to consider it in mathematical logic. Thus the task of explaining the nature of mathematical rigor falls to mathematical logic, and indeed may be regarded as its most essential problem. We understand this task as including the explanation of mathematical truth and the nature of mathematics generally. We express this by saying that mathematical logic includes the study of the foundations of mathematics.
Mathematical logic is also part of the mathematical underpinnings of computer science.5
To summarize the main points, mathematics is a written language. It has a syntax and a semantics. It is used to establish theorems by means of logical proofs. Formulas and equations are expressions in this language. Computations and algorithms are elements of this language which are used to solve problems.
3. Mathematicians have defined their requirements for a procedure to be accepted as a mathematical algorithm.
If we seek a definition in the sense of a short dictionary-like description of an algorithm we won't find one which is universally accepted. But if we read textbooks of computation theory and mathematical logic we find full text descriptions of what it takes for a procedure to be a mathematical algorithm. These descriptions vary in their choice of words and some authors mention aspects others omit. It is best to read a few of them to obtain a complete picture.
Here are the collection of requirements for a procedure to be an algorithm which are mentioned by one or another of the authors cited in the footnote.6
Procedures to actually solve a category of problems
An algorithm is a procedure intended to actually solve a category of problems. It takes one of more inputs describing the specific problem and it produces the corresponding solution. This means the procedure is meant to be carried out, at least in principle if not in practice. If it is followed without error it will produce the correct answer. Stoltenberg-Hansen, Lindström and Griffor explain:7 (emphasis in the original)
An algorithm for a class K of problems is a method or procedure which can be described in a finite way (a finite set of instructions) and which can be followed by someone or something to yield a computation solving each problem in K.
Mathematicians sometimes call algorithms "effective procedures". This concept is broadly defined in intuitive terms because it is intended to be open ended. Researchers constantly discover new ways of defining and carrying out procedures able to actually solve problems. Their notion of algorithm isn't strictly defined because they don't want to exclude from the concept these future discoveries. When they need mathematical rigor mathematicians study specific models of computations like Turing machines, recursive functions or λ-calculus.
Manipulation of symbols
All algorithms are ultimately procedures for manipulating symbols. Stoltenberg-Hansen, Lindström and Griffor explain:8 (emphasis in the original)
It is reasonable to assume, by the intended meaning of an algorithm explained above, that each problem in K should be a concrete or finite object. We say that an object is finite if it can be specified using finitely many symbols in some formal language.
Sometimes we encounter a discussion of algorithms which presumes the computations are about numbers. For a mathematician the two concepts of arithmetic and symbolic computations are equivalent.
Boolos, Burgess and Jeffrey explain one aspect of this equivalence by pointing our that ultimately numbers must be represented by means of symbols when doing arithmetic calculations:9 (emphasis in the original, link added)
When we are given as argument a number n or pair of numbers (m, n), what we in fact are directly given is a numeral for n or an ordered pair of numerals for m and n. Likewise, if the value of the function we are trying to compute is a number, what our computations in fact end with is a numeral for that number. Now in the course of human history a great many systems of numeration have been developed, from the primitive monadic or tally notation, in which the number n is represented by a sequence of n strokes, through systems like Roman numerals, in which bunches of five, ten, fifty, one-hundred, and so forth strokes are abbreviated by special symbols, to the Hindu-Arabic or decimal notation in common use today.
Conversely, the same authors explains that symbols may be represented as numbers. Then symbolic computations may be defined in terms of arithmetical calculations:10 (emphasis in the original, link added)
A necessary preliminary to applying our work on computability, which pertained to functions on natural numbers, to logic, where the object of study are expressions of a formal language, is to code expressions by numbers. Such a coding of expressions is called a Gödel numbering. One can then go on to code finite sequences of expressions and still more complicated objects.
This may sound as a chicken and egg problem. Which is defined first? The manipulation of symbols or the manipulation of numbers? Actually is is impossible to manipulate numbers directly without first representing them as symbols of some sort. Even when a computation is defined as an operation of arithmetic it is ultimately a manipulation of symbols.
Finite description
An algorithm must be described with a finite number of symbols.11 It is not possible to learn and execute an procedure whose description is infinite. This requirement may seem obvious but much of mathematics is about infinite structures, like the set of natural numbers or the decimal expansion of pi. Mathematicians felt the need to set this boundary for themselves.
Precise definition
The steps must be defined precisely so we know exactly how to execute them. Boolos, Burgess and Jeffrey describe this requirement as follows:12
The instruction must be completely definite and explicit. They should tell you at each step what to do, not tell you to go ask someone else what to do, or to figure out for yourself what to do: the instructions should require no external source of information, and should require no ingenuity to execute, so that one might hope to automate the process of applying the rules, and have it performed by some mechanical device.
Actual execution
A procedure doesn't solve a problem unless and until it is actually executed. The requirements finite description and precise definition are meant to instruct exactly how the procedure should be executed.13
This requirement of actual execution has a consequence. An algorithm imposes a burden on the computing agent that executes it. The steps must be actually carried out and the symbols must be actually written. This burden is called computational complexity. It is measured by the number of steps which must be executed and by the amount of writing space required to write the symbols. This burden typically vary according to the size of the inputs. When the number of symbols in the inputs is larger the number of steps and the storage space required to read and process the inputs will also increase.
Independence from physical limitations
Mathematicians assume the agent executing the algorithm has unlimited time to carryout the computation and unlimited space to write symbols while computing. The goal is to separate the mathematical properties of the algorithm from the physical resources available to compute. Boolos, Burgess and Jeffrey describe this requirement as follows:14 (emphasis in the original)
There remains the fact that for all but a finite number of values of n, it will be infeasible in practice for any human being, or any mechanical device, actually to carry out the computation: in principle it could be completed in a finite amount of time if we stayed in good health so long, or the machine stayed in working order so long; but in practice we will die, or the machine will collapse, long before the process is complete. (There is also a worry about finding enough space to store the intermediate results of the computation, and even a worry about finding enough matter to use in writing down these results: there is only a finite amount of paper in the world, so you'd have to writer [sic] smaller and smaller without limit; to get an infinite number of symbols down on paper, eventually you'd be trying to write on molecules, on atoms, on electrons.) But our present study will ignore these practical limitations, and work with an idealized notion of computability that goes beyond what actual people or actual machines can be sure of doing. Our eventual goal will be to prove that certain functions are not computable, even if practical limitations on time, speed and amount of material could somehow be overcome, and for this purpose the essential requirement is that our notion of computability not be too narrow.
It is understood that an algorithm will be carried out in practice by a computing agent with finite amount of time and writing space, therefore the computation can only be done for a "finite number of values of n" as Boolos and al. put it. This doesn't mean the calculation isn't done according to the algorithm. It means that the algorithm is carried out only to the extent that sufficient resources are available. When the resources are exhausted the calculation stops prematurely and the answer is not reached.
For example consider the ordinary pencil and paper procedure of arithmetic for adding numbers. It is designed to produce the correct answer no matter how many digits are required to write the numbers. If the numbers have one trillion digits it may not be realistic to expect a live human to complete the task. Mathematicians still regard this procedure as a mathematically correct algorithm for addition. They consider that finding a computer powerful enough to carry out the task until completion is a separate issue from finding a mathematically correct procedure.
The purpose of this abstraction is to study the mathematical properties of the computation in itself, independently from the limitations of the computing agent. For example mathematicians want to know when a function cannot be computed at all regardless of the physical resources available. And they want to be confident that the algorithm produces the correct answer for all inputs. This procedure gives us a mathematical guarantee that an increase of the capabilities of the hardware will increase the range of computations which are practical without introducing errors because the algorithm is not limited to the capabilities of the current hardware.
Termination
This requirement is controversial.15 In some flavors of 'algorithm' it is omitted.
People who expect the algorithm to actually produce the answer demand that there is a point in time where the answer is available. This means there must be a finite number of steps after which the procedure is completed and the answer is available. But there are useful computational procedures which cannot meet this requirement. Stoltenberg-Hansen, Lindström and Griffor explain:16 (emphasis in the original)
The requirement that an algorithm should solve each problem in a class K is actually a requirement on the class K (to be algorithmically decidable) rather than on the concept of an algorithm. Indeed the notion of an algorithm is partial by its very nature. Regarding an algorithm as a finite set of instructions, there is certainly no a priori reason to expect the computation, obtained from applying the algorithm to a particular problem, to terminate.
An example is a procedure for computing the decimals of pi. This calculation can never be carried out until the end because there are infinitely many decimals. On the other hand it can compute the decimals of pi to an arbitrary degree of precision if we have the patience to carry it out long enough.
The main mathematical models of computation17 have the ability to define both algorithms which terminate and computational procedures which don't terminate.
Deterministic execution
This requirement is controversial.18 In some flavors of 'algorithm' it is omitted.
Some people expect the requirement of precise definition to imply that every step be deterministic, with no random element. But there are useful computational procedures that involve probabilistic steps, that is some steps have an outcome randomly selected from a predefined set of possibilities. This is called a randomized algorithm.
It is well know that a randomized algorithm can be transformed into a deterministic algorithm when a source of random numbers is available as an input. Then the random element is moved out of the calculation to the source of input. The calculation itself is deterministic relative to the input. Alternatively, pseudo-random number generators may be used to simulate nondeterminism by deterministic means.
4. Algorithms are machine-implementable because they rely only on syntax to be executed, but they solve problems because they implement operations of arithmetic and logic on the meaning of the data.
The requirement of precise definition permits the machine execution of algorithms. See the preceding quote of Boolos et al. An alternative statement of this requirement is given by Stephen Kleene as follows:19
In performing the steps we have only to follow the instructions mechanically, like robots; no insight or ingenuity or intervention is required of us.
If the meanings of the symbols are ambiguous it is impossible to execute the algorithm in this manner. Resolving the ambiguity is an intervention that requires insight or ingenuity. This requirement would not be met. On the other hand if the symbols are unambiguous, for purposes of executing an algorithm mechanically, like robots, their meanings are superfluous. For example, when evaluating a single bit there is no need for the step of noticing the symbol means the boolean value true when we already know the symbol is the numeral 1 because this numeral always means true in boolean context.
For the sake of comparison, here is an example of a procedure which is not an algorithm: Interim Examination Instructions For Evaluating Subject Matter Eligibility Under 35 U.S.C. § 101 (PDF). Legal procedures such as this one require the human to consider the meaning of the information and then inject additional information based on his experience, knowledge, and convictions to reach a decision. They require a lot of insight and ingenuity to be executed and for this reason they are not mathematical algorithms.
A consequence of this requirement is that the algorithm operates only on the syntax of the mathematical language. It doesn't operate on the meaning. This point has been noticed by Richard Epstein and Walter Carnielli20, where they describe a series of models of computations used to define classes of algorithms:21
What all of these formalizations have in common is that they are all purely syntactical despite the often anthropomorphic descriptions. They are methods for pushing symbols around.
Human beings may be taught procedures to process data based on their meanings. Computers can't. They must be programmed to execute algorithms. This is a prerequisite for writing a machine executable program. If the procedure is not an algorithm it is not possible to program a computer for it.
But then what is the role of meaning? It defines the problem and its solution. There is a whole body of computation theory which analyzes computation from the point of view syntactic manipulations of symbols. But this literature is limited in the study of which problems are solved by these algorithms. For that we need the meaning.
The art of the programmer is to find an algorithm which corresponds to operations of arithmetic and logic that solves the problem.
As a first step the programmer must define how the data elements will be representing symbolically, with bits.22 This task is referred to with phrases such as: defining a data model, defining data structures and defining data formats. This task amounts to defining how to represent the problem and its solution in a suitable language of symbols. Then as a second step the programmer must find an algorithm operating on this data that will produce the correct outputs. This means the programmer must find a way to manipulate the symbols without referring to their meanings and still reach the correct answer. If the programmer fails to to find such a procedure he cannot write a machine executable program.
The connection between logic and data is key. Well chosen logical inferences can solve practical problems. They can be turned into algorithm using data types. Consider the following series of statements.
-
"Abraham Lincoln" is a character string.
-
"Abraham Lincoln" is the name of a human being.
-
"Abraham Lincoln" is the name of a politician.
-
"Abraham Lincoln" is the name of a president of the United States of America.
Each of them is attaching a data type to the character string "Abraham Lincoln". Most computer languages are only concerned with the data type in line 1. This is all they need to generate executable code. But logicians have been interested in more elaborate forms of data typing. Each of the statements mentions a valid data type in this logical sense. Logicians have noticed that data types corresponds to what they call "predicates" which are templates to form propositions that are either true or false. For example "is the name of a president of the USA" is a predicate. If you apply it to "Abraham Lincoln" you are stating the (true) proposition that "Abraham Lincoln" is the name of a president of the USA. And if you attach the same predicate to "Albert Einstein" you get a similar but false proposition.
When writing a program, programmers must first define their data. They don't just define the syntactic representation in terms of bits. They also define what the data will mean. A logician would say they define the logical data types, the predicates which are associated with the data. These predicates are documented in the specifications of the software, in comments included in the source code or in the names they give to the program variables. This knowledge is essential in understanding a program. However these predicates are not used for generating machine executable instructions. The predicates are not used by the computer for the manipulation of the symbols. During execution the predicates are implicit. They are defined by a convention the reader must know in order to be able to read the symbols correctly. They are for human understanding and verification that the program indeed does what it is intended to do.23 And they are also for the user of the program as he needs to understand the meanings of the inputs and outputs in order to use the program properly.
Data types in this extended logical sense relate to algorithms as follows. If you expect the data to be of some type, then the data is implicitly stating a proposition. You can tell which proposition by applying the predicate to the data. If you expect a quantity of hammers in your inventory and the data you get is 6, then you implicitly have a statement that you currently have 6 hammers in stock. All data is implicitly the statement of a proposition corresponding to its logical type.
When the algorithm process the data it implicitly carries out logical inferences on the corresponding propositions because a correctly working program must always produce data of the correct type. For example if you ask a program for the birth date of Theodore Roosevelt and the program returns October 27, 1858, it implicitly states that this is the birth date of Theodore Roosevelt because this is the proposition corresponding to the expected data type. The definition of correctness for a program is that it produces a logically correct answer. Programmers are well aware of this correspondence between predicates, data and correctness. They use it to design, understand and verify their programs.
There is a whole body of theory on how algorithms correspond to logic based on logical data types. The Curry-Howard correspondence is part of this theory. It works like a translation, similar to translating between Russian and Chinese, except that the translation is between two mathematical languages. If the algorithm is expressed in the language of λ-calculus then the Curry-Howard correspondence translates the algorithm into a proof of mathematical logic expressed in the language of predicate calculus. The translation works also in the other direction. Proofs of mathematical logic may likewise be translated into algorithms. In this sense an algorithm is really another expression for rules of logic. The difference is a matter of form and not substance.
As an alternative, when the algorithm is written in an imperative language instead of λ-calculus it may be assigned a logical semantics using Hoare logic. Poernomo, Crossley and Wirsing argue that Hoare logic is what the Curry-Howard correspondence becomes when it is adapted to imperative programs.24
To summarize the main points, algorithms are machine executable because their execution depends only on syntax with no need for a human to interpret their meaning. But they solve problems because the symbols have meanings.
5. All computations carried out by a stored program computer are mathematical computations carried out according to a universal mathematical algorithm.
Mathematicians have discovered that some algorithms have a universal property. They can compute all possible computable functions provided they are given some corresponding input called a program. Universal algorithms makes possible to build general purpose computers. When we have a machine able to compute a universal algorithm we can make it compute any function of our choosing by supplying it with the corresponding data. This is the difference between making a machine dedicated to carrying out a single algorithm and software.
When a general purpose computer built in this manner every program ends up being executed by the universal algorithm. Therefore every computation in is a mathematical computation according to a mathematical algorithm. This phenomenon is often referred to by the slogan "software is mathematics". This notion is often repeated on Groklaw.
Several universal algorithms are known. Here is a selection among the main ones.
There is SLD resolution which is used in the logic programming paradigm and languages such as
Prolog. SLD resolution is a universal algorithm which applies rules of logic to the data.25
In
functional programming
various implementations of
normal order β-reduction
are used.26 These
universal algorithms are used in languages derived from
λ-calculus
like
LISP.
Instruction cycles are the preferred universal algorithms for imperative programming which is the most widely used programming paradigm. Instruction cycles have both hardware and software implementations. A hardware implementation results into the
stored program computer architecture which is the dominant way of making general purpose programmable computers. Software implementations often take the form of virtual machines or bytecode interpreters.
The universal Turing machine plays an important role in the theoretical foundations of computer science. It played a role in the birth of computation theory. It has also been inspiration behind the invention of the stored program computer. Unlike the previously mentioned universal algorithm it is not used for actual computer programming.
When a universal algorithm is implemented in software the computer needs to be programmed twice. The first program uses the native instructions of the computer to implement the universal
algorithm in software. The second program is the data given to the software universal algorithm.
The instruction cycle works as follows, assuming a hardware implementation in a stored program computer.27
-
The CPU reads an instruction from main memory.
-
The CPU decodes the bits of the instruction.
-
The CPU executes the operation corresponding to the bits of the instruction.
-
If required, the CPU writes the result of the instruction in main memory.
-
The CPU finds out the location in main memory where the next instruction is located.
-
The CPU goes back to step 1 for the next iteration of the cycle.
As you can see, the instruction cycle executes the instructions one after another in a sequential manner. In substance the instruction cycle is a recipe to "read the instructions and do as they say". This instruction themselves don't execute anything. They are data read and acted upon by the CPU.28
Not all universal algorithms use instructions as their input as the instruction cycle does. It is incorrect to assume every computer program is made of instructions because some programming languages target universal algorithms that don't use instructions as their input.
B. Some Errors of Facts Found in Arguments About Software and Patents
This section enumerates a few errors of facts that poison the discussion about software and patents. It is subdivided in several subsections, each of them is dedicated to one error. We explain what the error is and how it poisons legal arguments about abstract ideas and their applications. Each subsection is a standalone argument. Each of the errors is damaging and must be corrected.
The overarching argument for this section B is that these errors have a cumulative effect. Collectively they solidify the erroneous notion that the functions of software are performed solely through the physical properties of electrical circuits. Each error either disregard or deny the role of symbols and their meaning in computer programming. Then, the cumulative effect is that the expression of an abstract idea is conflated with the application of an idea. As a result, oftentimes patents on the expressions of abstract ideas are granted because they have been mistaken for the applications of these ideas.
1. The proper understanding of the term "mathematical algorithm" is the one given by mathematicians.
Historically the courts have had problem understanding the term "mathematical algorithm". For example the Federal Circuit stated in
AT&T Corporation vs Excel Communications:
Courts have used the terms "mathematical algorithm," "mathematical formula," and "mathematical equation," to describe types of nonstatutory mathematical subject matter without explaining whether the terms are interchangeable or different. Even assuming the words connote the same concept, there is considerable question as to exactly what the concept encompasses.
Also see in re Warmerdam:
The difficulty is that there is no clear agreement as to what is a "mathematical algorithm", which makes rather dicey the determination of whether the claim as a whole is no more than that.
Part of the problem lies in the definitions they have used. Courts are not referring to the work of mathematicians when they try (and so far fail) to understand the meaning of this term.
In Gottschalk v. Benson the Supreme Court describes the term algorithm like this:
A procedure for solving a given type of mathematical problem is known as an "algorithm."
This is not an altogether wrong one-sentence summary, but it is too concise to be a complete definition. The details of the mathematically correct notion cannot be known if this sentence alone is used as the sole source of information.
In Typhoon Touch Technologies, Inc. v. Dell, Inc. the Federal Circuit explained their understanding:
The usage "algorithm" in computer systems has broad meaning, for it encompasses "in essence a series of instructions for the computer to follow," In re Waldbaum, 59 CCPA 940, 457 F.2d 997, 998 (1972), whether in mathematical formula, or a word description of the procedure to be implemented by a suitably programmed computer. The definition in Webster's New Collegiate Dictionary (1976) is quoted in In re Freeman, 573 F.2d 1237, 1245 (CCPA 1978): "a step-by-step procedure for solving a problem or accomplishing some end." In Freeman the court referred to "the term `algorithm' as a term of art in its broad sense, i.e., to identify a step-by-step procedure for accomplishing a given result." The court observed that "[t]he preferred definition of `algorithm' in the computer art is: `A fixed step-by-step procedure for accomplishing a given result; usually a simplified procedure for solving a complex problem, also a full statement of a finite number of steps.' C. Sippl & C. Sippl, Computer Dictionary and Handbook (1972)." Id. at 1246.
In particular the court in In re Freeman decided that these definitions of this term are more or less synonymous with process. Consequently the courts have tried to narrow down the understanding of mathematical algorithm to a subcategory of algorithms that the courts would deem "mathematical".
Because every process may be characterized as "a step-by-step procedure * * * for accomplishing some end," a refusal to recognize that Benson was concerned only with mathematical algorithms leads to the absurd view that the Court was reading the word "process" out of the statute.
This is where the problem occurs. The definitions the courts have used provide no insight into what makes an algorithm mathematical. As a result, the courts don't have the information they need to distinguish a mathematical algorithm from a process in the patent-law sense.
Mathematicians have told us what a mathematical algorithm is. The courts should use this definition. Then they would know what an algorithm is in the mathematical sense of the term.
A mathematical algorithm is a procedure for manipulating symbols which meet the additional requirements we have given above.29 We can ensure an algorithm is "mathematical" by verifying it meets the requirements of mathematics.
It happens that the computations carried out by a computer always meet these requirements. The slogan "software is mathematics" is often used to refer to this conclusion. We may reach that conclusion in several ways. For the purposes of this response, it suffices to mention three of them.
First, we may just compare the manipulation of bits in a computer with the requirements of mathematics to see that there is a match. An algorithm is a procedure that solves problem through the mechanical execution of a manipulation of symbols. A programmer must find a way to solve the problem exclusively by syntactic means, without having the machine to refer to the semantic. This obligation is what ensures the algorithm always meet the requirements of mathematicians for an algorithm to be a mathematical algorithm.
The second way to reach this conclusion is to observe that software is always data given as input to a universal algorithm. Given that the universal algorithm is mathematical then the computation must be the execution of a mathematical algorithm
A third way to reach a similar conclusion is to use a programming language approach. We may ask whether the claimed method is implementable in the Concurrent ML extension of the programming language Standard ML. The official definition of the language specifies in mathematical terms which algorithm must be executed when a program is executed. Concurrent ML extends this specification to input/output routines and various concurrent programming constructs. A program written in this language is guaranteed to correspond to a mathematical algorithm given by the definition of the language.30
The patent eligibility of a computer implemented invention hinges on whether the claim is directed at an application of the mathematical algorithm as opposed to the algorithm itself. A logical conclusion of "software is mathematics" in the sense above is that any threshold test of whether a mathematical algorithm is present in the invention is always passed when software is used. Attempts to distinguish computer algorithms that are 'mathematical' from those which are not are contrary to the principles of computer science. Then the section 101 analysis must proceed to whether the claim is directed to a patent-eligible application of the algorithm as opposed to the patent-ineligible abstract idea. A proposal for doing this will be presented in section C below.
2. The vast majority of algorithms can carried out in practice for smaller inputs and are impractical for larger inputs.
Mathematicians know that algorithms must be executed in practice in order to actually solve problems. A procedure which can't be actually carried out won't solve anything. But still they have made a conscious decision to ignore the practical limitations of the computing agent in their criteria for accepting a procedure as an algorithm.31 This is in direct conflict with a frequently stated legal argument. Some people argue that whether or not the computation can be implemented in practice is one of the distinguishing factors between abstract mathematics and an application of mathematics.32 In one version of this argument it is argued that if the algorithm is hard to implement in practice then this is evidence that it is not an abstract idea.
The problem with this argument is that the burden of carrying out the steps on an algorithm increases with the quantity of data present in the input. There are few exceptions, but typical algorithms require at least to read their inputs. Then logically, if the size of the inputs increases, more work is required to read them. Then the input must be processed and again the amount of work increases with the quantity of data to be processed. All typical algorithms are practical to use for a small enough size of inputs. And all typical algorithms are impractical when the size of the data grows over a certain limit. Therefore all typical algorithms will both pass and fail the "can be implemented in practice" test depending on the size of the input.
In particular all ordinary arithmetic calculations may be either practical or impractical depending on how many decimals are required to write the numbers. Doubling the number pi with a precision of one trillion decimals is not something a human doing pencil and paper calculations can achieve in his lifetime. A computer can do it but there is no limit to infinity. If we increase the number of decimals to a high enough value the calculation is impractical on the fastest computers. This statement will remain true no matter how powerful our computer may be because their capacity will always be finite.
This is the point of the abstraction mathematicians have made. By ignoring the practical limitations they separate the mathematical properties of the algorithm from the capabilities of the computing agent. A test of whether the method may be carried out in practice is not testing for what a mathematical algorithm actually is.
We may compare algorithms with legal arguments. Courts enforce limits on the number of pages a brief may have and on the duration of oral arguments. Lawyers must find concise arguments that fall within these limits. This is not inventing a smaller stack of paper covered with ink or a faster process for emitting sounds in a courtroom. The argument remains an abstract idea even though concision makes it fit within physical limits.
Computations are mathematical written utterances because they are procedures for writing symbols. When a better algorithm is found the utterances are more concise. This is still a mathematical algorithm. The comparison with a legal argument is applicable because according to the Curry-Howard correspondence an algorithm is an expression of logic.33 An algorithm solves problems precisely because it uses sound principles of logic and arithmetic to derive the solution.
3. The printed matter doctrine should be applicable to computations.
What happens when the only new and nonobvious advances over the prior art are in the meaning of the symbols? For books and printing processes there is the printed matter doctrine. It is well understood that stories of hobbits traveling in faraway countries are not physical elements of books or printing processes. The contents of the book cannot be used to distinguish the invention over the prior art.
As far as Groklaw can tell there is no analogous doctrine about computations carried out by computers. This is a problem. There should be one.
Please take a pocket calculator. Now use it to compute 12+26. The result should be 38. Now give some non mathematical meanings to the numbers, say they are counts of apples. Use the calculator to compute 12 apples + 26 apples. The result should be 38 apples. Doe you see a difference in the calculator circuit? Here is the riddle. What kind of non mathematical meanings must be given to the numbers to make a patent eligible difference in the calculator circuit? Answer: it can't happen.
This example carries to programming. There is no difference in the computer structure between an instruction to add 12+26 and an instruction to add 12 apples + 26 apples. There is no difference in a computer structure between doing a calculation for the same of knowing the numerical answer and doing a calculation because the numbers mean something in the real world. If we use a computer to compute the trajectories of satellites in orbit the satellite and their trajectories are not computer parts. There are only instructions for manipulating numbers.
There are two issues there. First, if meaning doesn't make a difference in the computer structure then we can't argue a new specific machine is made on that basis alone. Second the difference between a pure mathematical calculation and and application of mathematics is the meaning given to numbers and other mathematical entities in the real world.
When the innovation lies strictly in the meaning with no physical difference in the machine then there is no patentable invention. At the very least the invention cannot be a machine or the operating process of a machine. We need a doctrine analogous to the printed matter doctrine to recognize these situations.
Here is another way to make the same point. Consider this claim.
A [computer / printing press] comprising a printing device and a microprocessor configured to use the printing device to print the story of hobbits traveling in faraway countries to destroy an evil anvil.
The words in brackets indicate a choice. This claim may be written indifferently to a computer or a printing press. A computer may be connected to a printed. A printing press may have an embedded microprocessor to control it. Logically the printed matter doctrine should apply in both scenarios. Even if we assume that destroying an anvil instead of a ring is a new and nonobvious improvement over Tolkien's The Lord of the Ring both claims should still be invalid.
We have an example of a claim where the printed matter doctrine should be applicable to a programmed computer. This raises the issue of where and how do we draw the line between claims where this doctrine applies and where it doesn't.
Technology does not provide a way to draw this line. For example we cannot distinguish between instructions and data. It is always possible to program a printing process with instructions which in effect mean "print the letter T, print the letter h, print the letter e, etc" until the whole book is printed. Or alternatively we can use a universal algorithm which does not rely on instructions as its input to transform any algorithm into non executable data. If the test relies on a technological difference then no matter how the courts may wish to define this test programmers will be able to arrange matters in such manner that their program falls on the side of the line they want. But if the test doesn't rely on technology, it is hard to see how can it be argued that a machine or its operating process has been patented.
We can make the argument for a computing version of the printed matter doctrine in a third manner. Let's compare the printing process with computing. Printing is a physical process which is performed through the physical properties of ink and paper. This process functions automatically without the intervention of a human mind. The specific book being printed is determined by data given as input to the printing press.
In a stored program computer, the computation is carried out by executing the instruction cycle. This instruction cycle is a physical process which is performed through the physical properties of an electrical circuit. This process functions automatically without the intervention of a human mind. The specific calculation is determined by data given as input to the instruction cycle.
There is no factual difference which would justify applying the printed matter doctrine to a printing process but not to the instruction cycle. The relationship between the meaning of symbols and the machine is exactly the same in both cases.
The Federal Circuit guidance given in in re Lowry is unhelpful:
The printed matter cases "dealt with claims defining as the invention certain novel arrangements of printed lines or characters, useful and intelligible only to the human mind." In re Bernhart, 417 F.2d 1395, 1399, 163 USPQ 611, 615 (CCPA 1969). The printed matter cases have no factual relevance where "the invention as defined by the claims requires that the information be processed not by the mind but by a machine, the computer." Id. (emphasis in original).
It is hard to see how this guidance can work.
A claim on a
configured printing press
requires that the information be processed not by a human mind but by a machine, the printing press. The issue of meaning arise whether or not the human mind is an element of the process.
Software is much more likely to require the use of a human mind than a printing press. Many computer programs are interacting with their users, providing outputs and requiring inputs. In these circumstances part of the data processing is done by a human mind
because human decisions are involved.
On the other hand a printing press replicates the printed matter in an entirely automatic manner.
This is not the only flaw in
Lowry.
There isn't information useful and intelligible only to a human mind anymore. Authors write books using word processors. Books exist in electronic form and printing devices are controlled by computers. Printed
characters are machine readable through
optical character recognition (OCR)
technology. The
Perl programming language
has been designed for the express purpose of processing text and it can process the result of an OCR scan.
The preceding paragraph assumes that "intelligible to a machine" means the ability to recognize the characters and process their syntax. If "intelligible" means the faculty to relate the syntax with meaning computers don't do that.34 This is precisely why programmers must use algorithms to solve problems.35
The Lowry test for the applicability of the printed matter doctrine is arbitrary and illogical. It is not consistent with technological reality.
4. The language used in the disclosure and claims in software patents rely on an inversion of the normal semantical relationships between symbols and their meaning.
The error discussed in this section occurs when this inversion of the normal semantical relationship is not acknowledged. This leads to a contradictory reading of Supreme Court precedents on section 101 subject matter patentability. But if the inversion is taken into account it is easy to see that Supreme Court precedents are consistent.
Let's use ink and paper as an analogy. The marks of ink represent letters and the letters form words which have meanings. So the normal semantical relationship goes from the physical substrate, the ink, to the symbol, the letter. And then it goes from the letters to the words, from the words to the sentences and ultimately to the meaning of the sentences.
This observation is applicable to the mathematical foundations of computing. Mathematics is a written language. The semantical relationships follow the normal progression, from ink to the symbols, from the symbols to the syntax of mathematical language and then to the mathematical entities like numbers which are denoted by the symbols. Then there is an additional relationship between math and whatever in the universe is described by means of math.
This applies to algorithms too. An algorithm is a mathematical procedure to solve problems, like the ordinary pencil and paper arithmetical calculations we have learned in school. When computing the computer write symbols that have the same semantical relationships. An algorithm is a procedure for writing and rewriting the symbols until we arrive at a solution of the problem.
We find in computers the same semantical progression except that the symbols are not written on paper. Computers use electrical, magnetic and optical phenomenons to represent bits. The bits are symbols representing boolean values and numbers. Finally the numbers means whatever in the universe is described by the numbers. The computations are manipulations of the bits according to some algorithm. This is part of mathematical foundations of computer science.
Sometimes we may invert this semantical relationship. For example we may enter a bookstore and ask for the book where hobbits travel in faraway countries where live elves and orcs to destroy an evil ring. Then the store keeper will bring a copy of Tolkien's Lord of the Ring. This is describing the physical book by referring to its contents. Instead of using the book to tell the novel we use (an outline of) the novel to refer to the book.
This inversion of the semantical relationship occurs in software patents. The functions of the software are disclosed and claimed. This language is written in terms of the meaning of the data. If the patent is on a payroll system the functions of the software will be described in terms of employees, wages and deductions for example. The expectation is that a skilled programmer will be able to write the software from this disclosure. Also, the claim is presumed to describe a new machine which is a programmed computer. The claimed invention is either this machine or some machine process such as transistors turning on and off while carrying out the functions of the software. This is describing the physical device in terms of its meaning, exactly like the physical book may be described by an outline of the novel.
This point is related to the distinction between the expression of an abstract idea and an application of an idea. A mathematical idea is written using symbols. This is an expression of the idea in a sense close to copyright law. But mathematics may be used to describe something else, like a rocket in flight or the finances of a corporation. This is the application of mathematics. We can see these concepts are related to mathematical language. In semiotics terms, the expression of the idea is a sign-vehicle and the application is a referent.
A mathematical calculation involving pure numbers like 12+36=48 is not distinguishable from an applied calculation like 12 apples + 36 apples = 48 apples unless we consider the meaning of the numbers. In this example, the meaning is counts of apples. Therefore the difference between pure abstract mathematics and applied mathematics is in the meaning.
The same mathematical expression may or may not have a meaning outside of mathematics depending on context. It can be both pure mathematics or applied mathematics depending on what is the meaning. The same is true of algorithms. The same algorithm can be used for both pure mathematics and applied mathematics depending on the intent of its user. This supports the notion that an expression of a mathematical idea is a sign-vehicle and its application is a referent.
We may represent the inversion of semantical relationships in a picture:
This inversion is not a problem as long as everyone understand and acknowledge this is what is going on. The translation between the two views is straightforward and everybody will understand each other.
Problems occur when people are oblivious to the normal semantical relationships and only consider the legal view. Then they argue the computer is described by mathematics in a manner analogous to a description of the physical universe according to the laws of physics. Then they will treat the programmed computer as an application instead of an expression of mathematics. This conflation is indicated in the diagram above.
This argument is found explicitly in in re Bernhart:
[A]ll machines function according to laws of physics which can be mathematically set forth if known. We cannot deny patents on machines merely because their novelty may be explained in terms of such laws if we are to obey the mandate of Congress that a machine is subject matter for a patent.
A device described according to the laws of physics is the meaning of the mathematical language. It is not the language itself. But the computation as carried out by the computer is the actual manipulation of symbols representing numbers. They are the digital counterpart of pencil and paper calculations. This is illustrated in the picture below.

This picture shows the laws of physics follows the normal semantical relationships: from symbols to math and from math to the described device. But a patent goes the other way round because the programmed computer is where the symbols are stored and manipulated. The Bernhart law of physics argument is valid when applied to a device described according to the laws of physics. But when its is applied to a software patent claim this difference must be taken into account and the argument should not apply.
Let's use a payroll system as an example. The algorithm is described in terms of calculations about hours worked, hourly rates and deductions. None of that is machine parts. A payroll algorithm is not a mathematical description of the computer. It is a description of the calculations which are applicable to payrolls. We can use this as a description of the programmed computer only when we invert the semantical relationship and use the functions of the software as a description of what the computer must do with the bits. This is not like the laws of physics.
If we take the laws of physics argument seriously there is no arithmetic calculation which is abstract mathematics. The logic goes like this. All mathematical formulas may be used as a mathematical description of a programmed computer for doing the corresponding calculations. To paraphrase the court in Berhhart, we cannot deny patents on machines merely because their novelty may be explained in terms of such formulas if we are to obey the mandate of Congress that a machine is subject matter for a patent.
When we disregard the inversion of the semantical relationship an application of mathematics is incorrectly conflated with a written expression in the language of mathematics. Or in the terms of of semiotics, the sign-vehicle is conflated with the referent. This leads to a contradictory reading to the Supreme Court precedents in Gottschalk v. Benson,
Parker v. Flook and
Diamond v. Diehr. The factual difference between Diehr and the other two cases is that in Diehr the referent is claimed but it is not claimed in the other two cases. The only basis we have to find that there is an application of mathematics in Diehr but not in Benson and Flook is that the referent is claimed. This is consistent with the view that an application of mathematics is a referent while an expression of a mathematical idea is a sign-vehicle. But if we don't distinguish the expression from the application we cannot distinguish Benson and Flook from Diehr and the three cases are contradictory.
A contradictory reading of these cases cannot be correct. Therefore the proper interpretation of these cases should be that an application of a mathematical algorithm is a referent and not a sign-vehicle. This is also the conclusion which is reached when the proper semantical relationships are taken into consideration when we analyze how algorithms perform their functions.
5. In a stored program computer the functions of software are performed through a combination of defining the meaning of data and giving input to an already implemented algorithm.
The error in this section is a common misunderstanding of the operating principles of a computer. The courts have ruled that programming a computer is the act configuring a general purpose of computer into a specific machine for performing the functions of the software. This is the legal doctrine that programming a computer makes a machine different from the unprogrammed computer. This view is technically incorrect because the functions of software are not implemented in this manner. The consequence of this error is that patents are granted on machines when no machine has been invented.
There are two main arguments supporting this doctrine: the new function argument and the change to the machine structure argument.
According to the new function argument the configured circuit can perform a function the circuit without the configuration is not capable of performing. Therefore the configured circuit is a different circuit from the one without the configuration.
The change to the machine structure argument has been stated in
In re Bernhart
: "[I]f a machine is programmed in a certain new and unobvious way, it is physically different from the machine without that program; its memory elements are differently arranged."36
These two arguments follows from a naive and technically incorrect understanding of computer programming. In this understanding the functions of software are implemented by storing the instructions of the program in main memory. Then, according to this understanding, the structure of the general purpose computer is changed and it becomes a specific machine able to perform the functions of software. This view is incorrect because the functions of software are not related to the machine structure in this manner.
Some old general purpose computers like the
ancient ENIAC were programmed by physically rewiring the computer using a plug board. This kind of programming makes a particular circuit for each program. This is an obsolete design. Most modern general purpose computers are build according to the stored program computer architecture. They are not programmed with plug boards or equivalent devices. These computers are programmed through a combination of two techniques: (a) defining the meaning of data, and, (b) giving some input to an already implemented algorithm. These two techniques, taken alone or in combination, do not configure the computer to make a specific machine. They leave the structure of the machine unchanged.
The naive understanding of programing departs from the technically correct view in three ways.
-
The naive understanding of computer programming ignores the role of the meaning of data.
-
Main memory is a moving part of a computer. A physical change to a moving part of a machine doesn't make a structurally different machine. It is the action of the process by which the machine operates.
-
The mere act of storing data in memory does not implement functionality. This only happens when the data is given as input to an algorithm. This remains true when the data is instructions for a program.
-
All data may be used to implement functionality when given as input to an algorithm. This capability is not limited to instructions.
We illustrate these issues using a multiplication algorithm as an example. We assume the algorithm is implemented as a dedicated digital circuit for the sake of making clear what is the relationship between functionality and the underlying hardware. Then the explanation will also apply to the hypothetical specific machine which is created when a computer is programmed.
Our hypothetical circuit performs a series of multiplications. It takes as input a series of number, like 2, 5, 7, 12, 43, and multiply them by the same predefined number. The circuit is configured by recording this predefined number in a hardware register.37 If the number in the register is 2 then the circuit will double the sample series above to produce the result 4, 10, 14, 24, 86.
Let's call this circuit a multiplying circuit. Then we may write a series of claims:
-
A multiplying circuit comprising an arithmetic unit and a register configured to double a plurality of numbers.
-
A multiplying circuit comprising an arithmetic unit and a register configured to triple a plurality of numbers.
-
The multiplying circuit of claim 1 where the numbers are counts of apples.
-
The multiplying circuit of claim 2 where the numbers are counts of oranges.
-
A multiplying circuit comprising an arithmetic unit and a register configured to quadruple a plurality of counts of peppercorns.
The claims are directed to a hardware implementation of the algorithm. However the details of the hardware are purposefully left out of the claims. As they are written they may as well read on the specific machine that results, according to patent law, from the programming of a general purpose computer. This ambiguity is intended for educational purposes. It builds an easy to understand correspondence between the operation of the hardware and the action of the algorithm. Any argument about the hardware circuit obviously transposes to the equivalent software implementation.
Claims 1 and 2 illustrate the meaning of the phrase "configured to" when it is applied to a circuit for executing an algorithm. In claim 1 the function is doubling. In claim 2 the function is tripling.38 These functions are implemented by storing a number in the circuit register. For claim 1 this number is 2. The number is 3 for claim 2. Configuring circuits for performing some functions is the act of storing one or more numbers in a memory element. In the case of the multiplying circuit only one number is needed and the memory element is a register. In the case of a stored program computer we store long series of numbers in the computer main memory. Often the numbers represent instructions to be executed by the instruction cycle but this is not always the case. Often other numbers are used as inputs to other algorithms. For example this would occur in a software implementation of claims 1 and 2.
The naive understanding of computer programming ignores the role of the meaning of data.
Claims 3 and 4 show how the meaning of data relates to functionality. Claim 3 doubles counts of apples instead of doubling plain numbers as in claim 1. And claim 4 triples counts of oranges instead of tripling counts of plain numbers as in claim 2. The difference is strictly in the meaning of numbers. The physical configuration of the machine is unchanged when compared to claims 1 and 2. This method of implementing functionality is a pure operation of meaning.
There is no way to argue that defining the meaning of data makes a circuit different from the circuit without the meaning. We cannot argue there is a change to the machine structure because no change at all is made to the machine. Then arguing the circuit must be different because it performs a new function is nonsensical.39
This point alone suffices to refute the doctrine that programing a computer makes a different machine. The reason is that the meaning of numbers is not a machine part. The sole operation of giving some non-mathematical meaning to numbers can never make a machine different from the one where the numbers don't have this meaning.
In claim 5 the two programming techniques are used in combination. A number is configured in the register as input to the multiplying algorithm and simultaneously we define the numbers to be counts of peppercorns. Programs for general purpose computers use this same combination of techniques. The meaning of data is defined and numbers are stored in main memory and given as input to algorithms.
The contribution of the count of peppercorns to the circuit structure is nil. This is defining the meaning of the numbers like in claims 3 and 4. This claim doesn't recite a circuit different from a circuit configured to quadruple plain numbers. This same point is applicable to a stored program computer. Reciting the meaning of the data does not direct a claim to a computer different from one that manipulates plain numbers because meaning is not a machine part.
If someone were to insist on salvaging the doctrine from this argument, he may try to remove the meaning of data from the definition of the functionality and claim a specific machine for performing whatever remains of the function. This attempt would fail for two reasons. First for all practical purposes it would eviscerate the doctrine. Software is useless unless the data has meaning and utility is a requirement for patentability. Second once the meaning is removed the resulting function is a manipulation of plain numbers. Then the claim should be invalid because the mathematical algorithm exception applies.
A patentable application of mathematics must actually use the referent. Merely referring to it is not sufficient because, then, there is no contribution of the referent to the invention structure when compared to an identical manipulation of pure numbers.
Main memory is a moving part of a computer. A physical change to a moving part of a machine doesn't make a structurally different machine. It is the action of the process by which the machine operates.
The issue may arise of whether the changes to the memory elements resulting from programming the computer suffice to make machine different from the unprogrammed computer. The answer is that no such machine is made because memory elements are moving part of the circuit. They can be changed billions of times per second.40 Clearly a different machine isn't made every time one of these changes occur. To rule otherwise yields the absurd result that no machine can perform a computation until the end because it always become a different machine every time a memory element is altered.
Storing information in memory never makes a structural change to the computer. This action is always part of the execution of the electrical process by which the computer operates.41 Regardless of how a computer is programmed this electrical process is always the execution of the instruction cycle.
The mere act of storing data in memory does not implement functionality. This only happens when the data is given as input to an algorithm. This remains true when the data is instructions for a program.
If someone were to insist that programming a computer makes a different machine from the unprogrammed computer he has to argue that he can somehow distinguish some memory changes that make a different machine from other changes that don't.42 This argument is not defensible because the technology doesn't work in this manner.
Looking at claims 1 and 2 again, there is no physical difference between a number which is used to configure a multiplying circuit and a number which is used for another purpose. The bits representing the number are identical in both cases. The difference is in what is done with the number after it has been stored. If we transpose this logic to a stored program computer, there is no physical difference between numbers in memory which are instructions to the microprocessor and numbers which are used for another purpose. Again the bits representing numbers are identical. The difference is in what is done with the numbers afterwards.
There are programs which use instructions as ordinary numeric data without executing them. Examples are programs which compute
checksums or hash functions to verify that the file containing the instructions has not been tampered with. When instructions are stored in memory for this purpose the functionality is not imparted to the computer. The instructions will result into functionality only when they are given as input to the instruction cycle.
The changes in the memory elements do not impart functionality to a computer. The act of giving the data as input to an already implemented algorithm imparts the functionality. This is why we can't distinguish memory changes that makes a structurally different machine from those that don't. The difference is in how the data is used and not in which data is used or what happens to the memory.
All data may be used to implement functionality when given as input to an algorithm. This capability is not limited to instructions.
The naive view of computers asserts that because the instructions have a special meaning to the hardware they impart functionality while other data without such special meaning will not. This is not how its works. Instructions are series of numbers given as input to an algorithm implemented in hardware which is the instruction cycle.43 But this is only one of the several algorithms programmers may use for this purpose.44 Programmers can and do implement functionality with data which is not instructions recognizable by the hardware.
As a general rule every algorithm that accepts multiple arguments can be used to produce more functions by partially specifying one of its argument in the manner illustrated by claims 1 and 2. Any type of data can be used as an input as long as the chosen algorithm can process it.
The range of functions which can be so specified will vary depending on the capabilities of the algorithm. Some algorithms are especially prone to be used in this manner. The extreme case is the various universal algorithms mentioned in section A.5 supra. Each of these algorithms can compute all functions which are computable. But non-universal algorithms can also be used, although they are more limited in the range of what they can compute. For example algorithms for pattern matching using regular expressions can be used for a wide range of text processing functions. And algorithms for reading and writing data in a database can be used for a wide range of storage and retrieval functions. Please note how some of these algorithms accept as input data which is not instructions to the hardware.
Conclusion
The main memory of the computer is always a moving part of the device regardless of which type of information is stored and how it is used afterwards.45 Changing the contents of main memory never makes a structurally different machine. In addition defining the meaning of data makes no changes whatsoever to the computer. The doctrine that programming a computer makes a machine different from the unprogrammmed computer corresponds to a naive and incorrect view of how functionality relates to the underlying hardware. The effect of this doctrine is to incorrectly extend the patentability of machines to claims where the actual invention is clearly not a machine.
6. The meaning of data distinguishes an algorithm from an application of the physical properties of a machine.
The Court of Customs and Patents Appeals once said: (
In re Noll
)
There is nothing abstract about the claimed invention. It comprises physical structure, including storage devices and electrical components uniquely configured to perform specified functions through the physical properties of electrical circuits to achieve controlled results.
The functions of software are not always performed through the physical properties of electrical circuit. Software relies on the meaning of data and this is not a machine part. And most importantly, when data has no meaning, an algorithm doesn't solve its problem.
It is possible to view the computer as a machine that functions according to the laws of physics. It may be argued that the computer will functions without a human mind watching the meaning of the bits inside the computers. The same may be said of a printing press. In most software patents what is claimed is not the sole operation of the machine according to the laws of physics. Semantical elements are claimed. They are needed to infringe. This distinguishes the invention from a claim on a machine operating according to the laws of physics.
In sections B1 through B.5, five independent errors of fact have been identified. All five errors can be argued separately and they should all be corrected.
To make matters worse the role of meaning is not acknowledged. This sixth error seems to be a recurring theme underlying several of the previous five errors. This is a major problem because meaning is the very thing that makes computers useful. As a result, the subject matter of the invention is often mistaken for something physical when nothing physical has actually been invented.
The effect of the errors is cumulative. They prevent the patent system from understanding the difference between an abstract mathematical idea and the application of this idea.
C. What Is an Abstract Idea in Software and How Expressions of Ideas Differ From Applications of Ideas.
This section argues that semiotics is the proper approach to define what is an abstract idea in computer programming. Some alternative approaches are examined and rejected. This section also includes an examination of why mathematical subject matter is abstract and why the semiotics approach will correctly identify this type of abstract ideas.
1. Mathematical algorithms are abstract ideas.
It is understood in case law that mathematical algorithms are a subcategory of abstract ideas. We explain in this section how the principles of mathematics justify this view.
An algorithm is often abstract because it is designed to handle a potentially infinite range of inputs. This is the case of all arithmetic operations because there is no limit to how many digits a number may have. This is also the case of many nonnumerical algorithms such as searching text which are designed to work on arbitrarily large text. Planet Earth is not vast enough to make concrete implementations of "infinite". Data of arbitrarily large size are abstractions.
An algorithm is abstract because it is a procedure defined in terms that ignores the limitations of time and space of its practical implementation. It is designed to produce the correct answer for all size of inputs whether or not the resources to handle this input are available.46
An algorithm is a procedure for manipulating symbols. We note that a symbols is an abstract entity is different from a mark of ink on paper or an electric charge in a capacitor.47 The same algorithm may be implemented with a diversity of technologies where the same symbol has different physical representations. The algorithm is abstract because it is a manipulation of the abstract symbol. It is not a physical process for manipulating the physical representations.
An algorithm is abstract because its utility depends on meaning. The meaning of symbols is not a machine part. It is not a physical element of the machine.
Algorithms are analogous to novels, legal briefs and other forms of text. They have to be represented physically and yet they are abstract. Software patents often contain claims directed to the physical representations as long they convey the recited meaning. These claims are charades. They are attempts to preempt the underlying abstract ideas by claiming the physical means that are used to express them on the basis of their meanings.
2. Semiotics is the proper approach to define what is an abstract idea in software.
The question arises of how do we distinguish a claim on an abstract idea such as a mathematical calculation from a claim on an application of the idea. We argue that the proper way to answer this question is to use the concepts and vocabulary of semiotics,48 as in the picture below.
We rely on the notion that mathematics is a language and a computation is a written expression on this language. The symbols must be written somehow, often with pencil and paper, but also by electronic meas in a computer. The computation itself is a manipulation of symbols in this language. The symbols represent various mathematical entities like numbers and boolean values. If mathematics is used for a practical application these abstract mathematical entities model something in the physical reality.
In semiotics term the computer is a sign-vehicle, a physical device used to represent the sign. Whatever physical reality is referred to by the data is a referent. In-between the abstract mathematical ideas are interpretants. They are thoughts in the mind of the programmer, or in the mind of the user of the computer.
There is room to argue whether a number is an interpretant, a thought in the mind of humans, or an abstract referent, something that exists in a parallel abstract universe. This is a controversial topic in the philosophy of mathematics. A similar question may be raised with such concepts as commodity hedging. The law shouldn't be concerned with this debate. Either way the mathematical entities are abstract and not patentable. It should be acceptable to assimilate abstract referents with interpretants for legal purposes.
The Supreme Court in Diamond v, Diehr said: (footnote omitted, bold added)
We recognize, of course, that when a claim recites a mathematical formula (or scientific principle or phenomenon of nature), an inquiry must be made into whether the claim is seeking patent protection for that formula in the abstract. A mathematical formula as such is not accorded the protection of our patent laws, Gottschalk v. Benson, 409 U. S. 63 (1972), and this principle cannot be circumvented by attempting to limit the use of the formula to a particular technological environment. Parker v. Flook, 437 U. S. 584 (1978). Similarly, insignificant postsolution activity will not transform an unpatentable principle into a patentable process. Ibid. To hold otherwise would allow a competent draftsman to evade the recognized limitations on the type of subject matter eligible for patent protection. On the other hand, when a claim containing a mathematical formula implements or applies that formula in a structure or process which, when considered as a whole, is performing a function which the patent laws were designed to protect (e. g., transforming or reducing an article to a different state or thing), then the claim satisfies the requirements of § 101.
Please refer to the part in bold. We argue that this kind of structure or process must be a referent. It cannot be a sign-vehicle such as a programmed computer because it is a representation of the mathematical language itself. A sign-vehicle is not an application of the language. To hold otherwise would allow to claim mathematical subject matter because an expression in the language must always have some form of physical structure. Whenever the claim is directed to a sign-vehicle an inquiry must be made into whether the only nonobvious advances over the prior art are interpretants. If this is the case the claim is directed to the abstract meaning of the mathematical language.
3. This description of abstract ideas is technology neutral and it doesn't require to determine whether the algorithm is 'mathematical'.
Mathematics is mentioned in this discussion in part because algorithms are the only type of procedures computers are capable of executing49 and in part because a mathematical algorithm exception has been created by Supreme Court precedents. But the semiotics approach is applicable to all manipulations of symbols whether or not they are mathematical. Therefore, if this approach is adopted, the issue of whether or not a mathematical algorithm is involved can be eschewed.
This semiotics approach is not limited to software. It is applicable in all circumstances where a sign is involved. It doesn't matter if the sign is a stored program computer or some other technology like a dedicated circuit. The issue of meaning is handled in the same manner.
These circumstances are advantageous. There is no need to design some special test on what is 'mathematical' or what is 'software'. Also the notions of semiotics are not that hard to understand and they require no deep knowledge of mathematics or computer science. This leads to a test for abstract ideas which is workable for judges and juries with little or no mathematical and technology background. This test is also consistent with the established printed matter case law.50 It helps draw a logical boundary between copyright and patent law because it distinguishes the expression of an idea from the application of the idea.
4. There is no alternative to this description of abstract ideas.
Previous attempts to test for "abstract ideas" in software have failed. All these attempts have disregarded the issue of meaning. No test will succeed until the role of meaning is taken into consideration. The problem is that every expression of an idea must have a physical representation. Then it is easy to give a claim preempting an abstract idea a façade of concreteness by directing it to a sign-vehicle defined by its meaning. It is impossible to analyze the subject matter of this type of claims unless it is recognized that they are sign-vehicles and they have meanings.
Abstract is not synonymous with "vague or overly broad". Mathematical subject matter such as algorithms is abstract but it is narrowly and precisely defined.51
Abstract is not the opposite of "useful". The contents of a reference manual or a dictionary is useful but it is an interpretant which is an abstract idea. Also the ordinary pencil and paper procedures for arithmetic calculations are abstract mathematical algorithms and they have practical uses in accounting, engineering and many other disciplines.
Tests based on whether the invention is practically difficult to implement don't work because most mathematical algorithms are practical to implement when the size of the input is small enough and practically impossible to implement when the size of the input is large enough.52
The Federal Circuit has tried for years to find a definition of what makes an idea abstract. They report that they have failed.
From MySpace, Inc. v. GraphOn Corp.:
When it comes to explaining what is to be understood by "abstract ideas" in terms that are something less than abstract, courts have been less successful. The effort has become particularly problematic in recent times when applied to that class of claimed inventions loosely described as business method patents. If indeterminacy of the law governing patents was a problem in the past, it surely is becoming an even greater problem now, as the current cases attest.
In an attempt to explain what an abstract idea is (or is not) we tried the "machine or transformation" formula--the Supreme Court was not impressed. Bilski, 130 S.Ct. at 3226-27. We have since acknowledged that the concept lacks of a concrete definition: "this court also will not presume to define `abstract' beyond the recognition that this disqualifying characteristic should exhibit itself so manifestly as to override the broad statutory categories of eligible subject matter… ." Research Corp. Techs., Inc. v. Microsoft Corp., 627 F.3d 859, 868 (Fed.Cir.2010).
Our opinions spend page after page revisiting our cases and those of the Supreme Court, and still we continue to disagree vigorously over what is or is not patentable subject matter. See, e.g., Dealertrack, Inc. v. Huber, ___ F.3d ___ (Fed. Cir.2012) (Plager, J., dissenting-in-part); Classen Immunotherapies, Inc. v. Biogen IDEC, 659 F.3d 1057 (Fed.Cir.2011) (Moore, J., dissenting); Ass'n for Molecular Pathology, 653 F.3d 1329 (Fed.Cir. 2011) (concurring opinion by Moore, J., dissenting opinion by Bryson, J.); see also In re Ferguson, 558 F.3d 1359 (Fed.Cir. 2009) (Newman, J., concurring).
This effort to descriptively cabin § 101 jurisprudence is reminiscent of the oenologists trying to describe a new wine. They have an abundance of adjectives--earthy, fruity, grassy, nutty, tart, woody, to name just a few--but picking and choosing in a given circumstance which ones apply and in what combination depends less on the assumed content of the words than on the taste of the tongue pronouncing them.
From CLS Bank International v. Alice Corporation PTY. LTD.:
The abstractness of the "abstract ideas" test to patent eligibility has become a serious problem, leading to great uncertainty and to the devaluing of inventions of practical utility and economic potential. See Donald S. Chisum, Weeds and Seeds in the Supreme Court's Business Method Patent Decision: New Directions for Regulating Patent Scope, 15 Lewis & Clark L. Rev. 11, 14 (2011) ("Because of the vagueness of the concepts of an `idea' and `abstract,'… the Section 101 abstract idea preemption inquiry can lead to subjectively-derived, arbitrary and unpredictable results. This uncertainty does substantial harm to the effective operation of the patent system."). In Bilski, the Supreme Court offered some guidance by observing that "[a] principle, in the abstract, is a fundamental truth; an original cause; a motive; these cannot be patented, as no one can claim in either of them an exclusive right." Bilski II, 130 S. Ct. at 3230 (quoting Le Roy v. Tatham, 55 U.S. (14 How.) 156, 175 (1852). This court has also attempted to define "abstract ideas," explaining that "abstract ideas constitute disembodied concepts or truths which are not `useful' from a practical standpoint standing alone, i.e., they are not `useful' until reduced to some practical application." Alappat, 33 F.3d at 1542 n.18 (Fed. Cir. 1994). More recently, this court explained that the "disqualifying characteristic" of abstractness must exhibit itself "manifestly" "to override the broad statutory categories of patent eligible subject matter." Research Corp., 627 F.3d at 868. Notwithstanding these well-intentioned efforts and the great volume of pages in the Federal Reporters treating the abstract ideas exception, the dividing line between inventions that are directed to patent ineligible abstract ideas and those that are not remains elusive. "Put simply, the problem is that no one understands what makes an idea `abstract.'" Mark A. Lemley et al., Life After Bilski, 63 Stan. L. Rev. 1315, 1316 (2011).
In section B supra we have identified that the source of these problems is the refusal to acknowledge the role of symbols and their meaning in computer programming. There is a failure to consider what is a algorithm in mathematics.53 Had this notion been considered the role of symbols and meaning would have been apparent. Then there is a failure to recognize the similarities between the computer instruction cycle and a printing process.54 This recognition too would have made apparent the role of symbols and their meaning. There is also the failure to acknowledge that the language of a typical software patent inverts the normal semantical relationships between a sign-vehicle and the referent. This failure yields an inconsistent reading of the Supreme Court precedents of Benson, Flook and Diehr.55 It also leads to the incorrect conclusion that the functions of software are performed exclusively through the physical properties of electrical circuits.56 This conclusion is cemented by the doctrine that programming a computer makes a machine structurally different from the unprogrammed computer.
The cure is to acknowledge the linguistic aspects of mathematics and take into account that a computer is a sign-vehicle. It is a device for manipulating bits and bits are symbols with meanings. Then the proper definition of abstract ideas becomes apparent.
D. The Effect on Innovation of Patent Rights Granted on the Expressions of Abstract Ideas.
Software patents don't promote innovation because they can't. The burden imposed on job creating software authors is large. They cannot possibly clear all rights to their own products. The consequences are deleterious. Not only software authors can't be secure in their own property but they can't use the disclosure from patents by fear of being liable for treble damages. In addition, the normal costs/benefits analysis of patents is not applicable to software development. None of the factors that normally allow patents to promote innovation function according to theory in the computer programming art. Therefore there is no reason to believe software patents promote innovation.
1. Clearing all patents rights on expression of ideas is overly burdensome.
Let's imagine a regime where proprietary rights may be granted to each particular idea. In this imaginary regime the author of a book, any book, would be required to secure the rights to each idea he is using. Each sentence expresses an idea which may be owned by someone. Each combination of sentences makes a more complex idea. The author is expected to check each of these ideas, determine whether it is in the public domain or if it is owned by someone, and in the latter case secure the rights to the idea or remove it from his work.
It is not realistic to expect authors to comply with this requirement because it is overly burdensome. The rights cannot be cleared because the number of ideas in a book is just to great to check them all. Authors would have to choose between to quit writing or risk being sued. This regime would hinder the creation of new works of authorship because it would put all the authors who choose to keep writing at a perpetual risk of infringement.
This is exactly the kind of regime patent law imposes on computer programmers. Case law doesn't recognize that a computation is the expression of an idea, exactly like English sentences in a book. This is wrong. Programs are useful because data has meaning. They solve problems because the computation implements operations of logic through a syntactic manipulation of symbols.57
Software is written in the form of lines of code. The source code is a copyrightable expression and it is not patented. But source code corresponds to a computation. Because the computation is a manipulation of symbols it is also an expression of an idea. Patents rights are granted to this expression and this is where the problem lies.
Each line of code is roughly similar to a sentence in English in that each of them expresses an idea. Like sentences, lines of code are grouped to make more complex ideas. But under the current case law every single one of these ideas is specifying a physical process which is performed through the physical properties of an electrical circuit. Each of these processes may be the subject matter of a patent. Typical software has between thousands and millions of lines of code. The number of ideas which may potentially infringe on someone's patent is enormous.
Mark Lemley quantifies the numbers of patents which may be applicable to a software product.58
Because computer products tend to involve complex, multi-component technology, any given product is potentially subject to a large number of patents. A few examples: 3G wireless technology was subject to more than 7000 claimed "essential" patents as of 2004; the number is doubtless much higher now.72 WiFi is subject to hundreds and probably thousands of claimed essential patents.73 And the problem is even worse than these numbers suggest, since both 3G wireless technology and WiFi are not themselves products but merely components that must be integrated into a final product. Some industry experts have estimated that 250,000 patents go into a modern smartphone.74 Even nominally open-source technologies may turn out to be subject to hundreds or thousands of patents.75 The result is what Carl Shapiro has called a "patent thicket"-- a complex of overlapping patent rights that simply involves too many rights to cut through.76
----
______________
[Footnotes]
[72] For discussion and sources, see Mark A. Lemley & Carl Shapiro, Patent Holdup and Royalty Stacking, 85 Tex. L. Rev. 1991 (2007). Information on patents essential to 3G wireless technology is collected at http://www.3gpp2.org/, though that includes only patent disclosed to that group.
[73] Ed Sutherland, WiMax, 802.11n Renew Patent Debate (Apr. 7, 2005),
http://www.wifiplanet.com/columns/article.php/3495951.
[74] See http://googleblog.blogspot.com/2011/08/when-patents-attack-android.html (statement of David Drummond, Chief Legal Officer at Google).
[75] Id. (discussing patents that threaten the open-source Android operating system). Microsoft, Nokia, Apple and others have all filed suit against makers of Android phones, part of a crazy tangle of litigation.
See http://www.flickr.com/photos/
floorsixtyfour/5061246255/.
[76] Carl Shapiro, Navigating the Patent Thicket: Cross Licenses, Patent Pools, and Standard-Setting, in 1 Innovation Policy and the Economy 119 (Adam Jaffe et al. eds., 2000). See also Michael Heller & Rebecca S. Eisenberg, Can Patents Deter Innovation? The Anticommons in Biomedical Research, 280 Sci. 698 (1998).
Christina Mulligan and Timothy B. Lee have observed59 the burden of compliance with patents depends primarily on two numbers: the number of patents which may be potentially infringed and the numbers of firms which write software. Both numbers are large. Over 40,000 software patents are granted every year in the US. Also every firm having an internal IT department develops software. It is common even for small enterprises to own a web site. Each of these firm may potentially infringing on some software patent and in an ideal world each of them must check all applicable patents for possible infringement. The size of the task is staggering:60
Even if a patent lawyer only needed to look at a patent for 10 minutes, on average, to determine whether any part of a particular firm's software infringed it, it would require roughly 2 million patent attorneys, working full-time, to compare every firm's products with every patent issued in a given year.
This calculation covers just the work of keeping up with the newly issued patents every year. Checking already issued patents is not included.
This result is justified by simple arithmetic. The assumptions are 40,000 patents issued per year, 600,000 firms that actively write software, and each attorney is capable of working approximately 2000 billable hours per year. Then the math is straightforward: 40,000 patents*600,000 firms*(10 minutes per patent-firm pair)/(2000*60 minutes per attorney)=2 million attorneys.
These assumptions are admittedly speculative. It doesn't matter. There are only roughly 40,000 registered patent attorneys and patent agents in the US. Even if we alter the assumptions by a large margin the patent bar clearly doesn't have enough members to perform the task.
Even if we consider only the work required within a single organization, this is still an overly burdensome task. Mulligan and Lee examine a simple hypothetical scenario where 30,000 firms making widgets own one patent each for a total of 30,000 patents. Then they inquire how mush work it is for each participant to evaluate whether they infringe on the remaining 29,999 patents.61
Each of the 30,000 firms would need to hire a patent attorney to examine 29,999 other patents, which takes 1 hour per patent, so attorneys would spend a total of 30,000 * 29,999 * 1 hour = 899,970,000 hours. Assuming a typical attorney bills 2000 hours of work per year, each firm would need just shy of 15 attorneys to examine 29,999 patents.
This analysis assumes each firm want to complete the work in exactly a year. It also assumes that lawyers can determine whether a given patent is infringed. This is not always the case. It is notorious that this kind of analysis is not dependable.62
The analysis also assumes software firms can wait until the analysis is done before releasing their products in the marketplace. This is usually not the case. There is a strong first mover advantage in the software industry. Delays may jeopardize the commercial success of the product. Releasing the software before the patent search is completed may lead to a finding of willful infringement and treble damages. A company may be better off not to search for patents at all than release a product before the search is completed.
Also, patent compliance is not a one-time event. Software is constantly being modified. Products are constantly being upgraded. It is commonplace to release so-called "beta-tests", that is unfinished versions of the product for the purpose of testing. After one or more such testing releases an official version is produced. Then various bug fixes are released. Some of them are security fixes and must imperatively be released immediately because any delay leaves the customers at risk. Eventually upgrades to new versions are developed. Each release may potentially introduce a patent infringing change. In an ideal world legal analysis must be constantly done to keep the software non infringing on a timely basis.
The cumulative effect of all these constraints ensures that clearing all rights to one's own product is a practically impossible task. This is not a problem that can be solved with faster better search engines for patents and prior art. Even with perfect information on all the applicable patents and all relevant prior art the sheer number of patents and the frequency at which they must be verified are too great. The burden is mostly a function of arithmetic.
If software authors wish to be active participant in the marketplace they have no choice but to ignore patents and operate at the risk of infringing. The only alternative is to stop writing software. Mark Lemley describes this situation thus:63 (footnotes omitted)
This is a particular problem for semiconductor, telecommunications, and software companies, which must aggregate hundreds or thousands of different components to make an integrated product. Each of those components may be patented, some by many different people. The threat that any one of those patent owners can obtain an injunction shutting down the entire integrated product allows them to extort settlements well in excess of the value of their patent. The patent damages rules similarly permit excessive recoveries, such as the recent $1.5 billion jury verdict against Microsoft for infringing one of many patents covering just one of many features of an add-on to the Microsoft Windows product. Patent law permits these product manufacturers to be found to be "willful" infringers liable for treble damages and attorneys' fees, even if they were unaware of the patent or even the patent owner at the time they began selling the product. And even if the manufacturer can avoid any of these risks by invalidating or proving noninfringement of each of these patents, doing so will cost millions of dollars per case in legal fees. Given these problems, it's a wonder companies make products in patent-intensive industries at all.
And yet make products they do. Both my own experience and what limited empirical evidence there is suggest that companies do not seem much deterred from making products by the threat of all this patent litigation. Intel continues to make microprocessors, Cisco routers, and Microsoft operating system software, even though they collectively face nearly 100 patent-infringement lawsuits at a time and receive hundreds more threats of suit each year. Companies continue to do research on gene therapy, and even make "gene chips" that incorporate thousands of patented genes, despite the fact that a significant fraction of those genes are patented. Universities and academic researchers continue to engage in experimentation with patented inventions despite the now clear rule that they are not immune from liability for doing so. John Walsh's study suggests that threats of patent infringement are not in fact responsible for deterring much, if any, research.
What's going on here? The answer, I think, is straightforward, if surprising: both researchers and companies in component industries simply ignore patents. Virtually everyone does it.
...
To get a perspective on how strange this might seem to an outsider to the patent system--or even to an outsider to the component industries in which this behavior is common--compare it to the world of real property. If I want to build a house, I'd better be darn sure that I own the land on which the house is built. In fact, it would be foolhardy to begin construction before I owned the rights to the land, in the hopes that I would be able to obtain the rights later. Nor would a prospective homebuilder put up with significant uncertainty about the boundaries of the land on which she was building. People don't often build houses that might or might not be on their land, hoping that they would ultimately win any property dispute. And even if a few people were so reckless as to want to do one of these things, banks won't fund construction without certainty in the form of a title insurance search report indicating that the builder unambiguously owns all the rights she needs.
Mulligan and Lee further explain:64 (footnotes omitted)
The tendency to implicitly assume that economic actors are omniscient is a common pitfall of theoretical social science. By definition, the theorist knows everything there is to be known about the stylized model he has invented. Theorists often implicitly assume that economic actors automatically have the information they need to make decisions. Indeed, this may be essential to building a tractable model of the world. But the failure to ponder the feasibility of acquiring and using information can lead to flawed conclusions.
The contemporary patent debate suffers from just this blind spot. Each patent is a demand that the world refrain from practicing a claimed art without the patent holder's permission. Potential infringers can only comply with this demand if they are aware of the patent's existence. On a blackboard or in the pages of a law review article, it's easy to implicitly assume that everyone knows about every patent.
But the real world isn't so simple. To avoid infringement, a firm must expend resources to learn about potentially relevant patents. Typically this means hiring patent lawyers to conduct patent searches, which may or may not be affordable or effective. In this paper, we'll call the costs of such information-gathering activities the patent system's "discovery costs." One criterion for a well- functioning patent system-- or any system of property-like rights-- is that discovery costs should be low enough that it's economically feasible for firms to obtain the information they need to comply with the law.
Thinking explicitly about discovery costs is a powerful tool for understanding the dysfunctions of the patent system. As we will see, discovery costs are relatively low in pharmaceuticals and other chemical industries. As a consequence, the patent system serves these industries relatively well. In contrast, discovery costs in the software industry are so high that most firms don't even try to avoid infringement. Unsurprisingly, software is a major contributor to the recent spike in patent litigation.
This situation is not fostering innovation. It imposes an unreasonable burden on job creating businesses that sell actual products. The only businesses who can be sure of owning all software patent rights to their products are those which don't make actual software and prefer to sell and license patents. This situation promotes monopolistic licensing rents and litigation.
2. Litigation risks are a burden to community-based software development.
Sharing ideas among a group of people is a very effective way to develop software. Several models of organizations have been invented for this purpose.
On possible model is the free and open source model.65 People agree on a copyright license and share source code.66 Everyone can download, run, debug and improve the programs. The improvements are contributed back to the community. Very innovative and commercially important software is developed in this manner.67
Another model is the definition of communication protocols by the IETF. The formal definition of the process is centered around specification documents called RFCs (Request for Comments).68 But in practice the source code for reference implementation is also frequently shared.69 All the core protocols of the Internet have been invented and standardized in this manner.
The problem of patents for these groups is the same as for anyone else. They can't verify they don't infringe someone else's patents. These groups can agree among themselves on whatever agreement they need to share the rights and function as a group. But they can verify they won't infringe on the rights of outside parties. They must take the risk and find out the hard way if someone will sue. Either that or they don't write the software.
This problem may be more acute for these groups than it is for proprietary vendors because these development model don't permit to pinpoint any specific date where the code is released. Every contribution from every member must be shared publicly the very moment it is made if the group is to function as a group. Since members may contribute something anytime they please new code is constantly being published. Public repositories such as github are used for this purpose. Hence, there is no publication event before which it could make sense to perform a legal review of the code.
This situation is hindering innovation. These collaborative groups have invented very influential technologies. The working methods of these groups are themselves innovative. The legal risks imposed on these groups by software patents are real. On the other hand the benefits are non-existent. Their goal is to develop software, disclose their inventions and share them with the world. They do this without the incentive of exclusive rights and they don't hide anything as trade secrets. And they can't opt-out of the patent system because they can't opt-out of inadvertently infringing on someone else's patent and being sued.
3. In the computer programming art, patents provide low quality disclosure which is legally dangerous for a programmer to read.
For a programmer, reading patents is legally dangerous. He risks becoming liable for treble damages for willful infringement. There is no hope to mitigate this risk by clearing all the patent rights to the software for the reasons explained above. The only effective mitigation strategy is not to read patents. But then disclosure is ineffective because it is intended precisely to be read by the developers. Patent law cannot promote innovation according to its theory unless the disclosure is read by the practitioners of the art.
Many Groklaw members report that their employers forbid their developers from reading patents because the legal risks are high and there are no benefits. This phenomenon has been reported by Mark Lemley as well:70 (footnotes omitted)
[B]oth researchers and companies in component industries simply ignore patents. Virtually everyone does it. They do it at all stages of endeavor. Companies and lawyers tell engineers not to read patents in starting their research, lest their knowledge of the patent disadvantage the company by making it a willful infringer. Walsh et al., similarly find that much of the reason university researchers are not deterred by patents is that they never learn of the patent in the first place. When their research leads to an invention, their patent lawyers commonly don't conduct a search for prior patents before seeking their own protection in the Patent and Trademark Office (PTO). Nor do they conduct a search before launching their own product. Rather, they wait and see if any patent owner claims that the new product infringes their patent.
Software patents are not only ignored as a property system. They are also ignored as a source of knowledge.
For programmer the preferred form of disclosure is the source code of a well written working program. If the license allows the programmer to modify the program and distribute the modifications it is even better. Communities of developers in FOSS projects do this on a routine basis.
Software patents do not require the disclosure of source code. Please see Fonar Corporation v. General Electric Corporation.
As a general rule, where software constitutes part of a best mode of carrying out an invention, description of such a best mode is satisfied by a disclosure of the functions of the software. This is because, normally, writing code for such software is within the skill of the art, not requiring undue experimentation, once its functions have been disclosed. It is well established that what is within the skill of the art need not be disclosed to satisfy the best mode requirement as long as that mode is described. Stating the functions of the best mode software satisfies that description test. We have so held previously and we so hold today. Thus, flow charts or source code listings are not a requirement for adequately disclosing the functions of software.
See also Northern Telecom v. Datapoint Corporation:
The computer language is not a conjuration of some black art, it is simply a highly structured language … . The conversion of a complete thought (as expressed in English and mathematics, i.e. the known input, the desired output, the mathematical expressions needed and the methods of using those expressions) into a language a machine understands is necessarily a mere clerical function to a skilled programmer.
From the perspective of a programmer these cases eviscerate the usefulness of disclosure. The functions of most software inventions can be defined after a few brainstorming sessions. Turning these functions into a working implementation is still a lot of hard work. When only the functions are known, the programmer is still required to do the bulk of this work. But this obligation does not follow from the disclosure which is commonly available from FOSS projects.
The functions of existing software can usually be seen just by watching the program in action. Developers may watch over the shoulder of a user, or they may inspect the computer internals with debugging tools. Disclosing the functions of software without source doesn't disclose any trade secret.
The ineffectiveness of disclosure has been noted by some patent scholars. For example Benjamin Roin states:71 (footnotes omitted)
If the Supreme Court is correct that "the ultimate goal" of patent law is to facilitate the disclosure of information that would otherwise be kept secret, then our patent system appears to be in trouble. A number of empirical studies suggest that patent disclosures play an insignificant role in promoting R&D spillovers. This is partially a reflection of the basic economics of patenting, where companies typically patent only those inventions that are disclosed to the public through other channels. It also reflects the numerous alternative sources of information available to inventors. Both of these issues are largely inherent in the patent system.
Many of the other problems discussed in this Note are more amenable to repair, assuming the courts and policymakers genuinely wish to improve the disclosure value of patents. The Federal Circuit's willful infringement rules, for example, encourage innovators to protect themselves from treble damages by remaining "willfully ignorant" of the patents in their field. Many commentators have recommended abolishing the willfulness rules entirely, although the Federal Circuit appears wedded to the doctrine. Similarly, commentators have suggested that Congress remove the remaining loopholes in the publication rules for patent applications, which currently allow some of the most time-sensitive innovations to be both patented and withheld from the public. In industries where patent applications are thought to disclose too little knowledge, courts might require more detailed information about how to enable the claimed invention. In the software industry, for example, there might be a strong case for requiring patent applicants to disclose the source code of their program.
Until these issues are fixed there is no point for a programmer in reading patents. He takes a huge legal risk and most of the time he doesn't learn anything that wouldn't otherwise be known to him without much effort.
4. The normal costs/benefits analysis of patents is not applicable to software.
The usual costs/benefits analysis is based on the patent quid pro quo. The inventor is granted exclusive rights for a limited period of time in exchange of the disclosure of his invention. Then, according to theory, society benefits from the invention when the exclusive rights expire. But during this time period the patentee may recoup his investment. This incentive to innovate is viewed as more advantageous for society than forcing the inventor to protect his invention with trade secrets.
The table below summarizes this analysis of the costs and benefits of patents.
|
Benefits to Society
|
Costs to Society
|
|
Promotes progress of useful arts by rewarding inventors
|
Grant of exclusive rights to the invention for limited time
|
|
Supports the economy by encouraging innovation
|
Administrative costs (we need a Patent office)
|
|
Disclosure of what would otherwise be trade secrets
|
Legal costs such as liability for infringement and patent defense strategies
|
But in the case of software this analysis is not applicable. There are strong incentives to innovate other than patents. Software is protected by copyrights. Software authors have a strong first-mover advantage.72 Community-based development like FOSS amounts to free R&D to organizations who know how to keep a good relationship with a community. Also Community-based development inherently provides superior disclosure.
The table below shows how the costs and benefits of patents are applicable to software. This table is very different from the previous one.
|
Benefits to Society
|
Costs to Society
|
|
Promotes progress of software by rewarding inventors above and beyond the rewards already provided by copyrights, first mover advantage and community contribution to FOSS projects
|
Grant of exclusive rights to the invention for limited time
|
|
Supports the economy by encouraging innovation above and beyond the rewards already provided by copyrights, first mover advantage and community contribution to FOSS projects
|
Administrative costs (we need a Patent office)
|
|
Disclosure of what would otherwise be trade secrets above and beyond disclosure inherent to the release of source code by FOSS projects, but only to the extent readers don't fear being liable to treble damages for willful infringement
|
Legal costs such as liability for infringement and patent defense strategies
|
|
|
Software authors are unable to clear the rights to their own programs because it is not practically feasible to do so.
|
|
|
Harm to collaborative development such as FOSS limiting its positive contribution to progress, the economy and to disclosure of source code
|
|
|
Exclusive rights granted to the expressions of abstract ideas impinge on individual Free Speech rights
|
We cannot presume software patents are promoting innovation according to the normal costs/benefits analysis because this analysis is not applicable to software. There is no reason to believe an analysis which takes all relevant factor in consideration will show a positive contribution to society. In particular the inability of software authors to clear the rights to their own product strongly suggests that the costs far outweigh the benefits.
Conclusion
The fundamental problem of the patentability of software is that the Federal Circuit (and the CCPA before them) believes that the functions of software are performed through the physical properties of electrical circuits.73 This belief leads to the natural conclusion that software is an electrical process and software patents are not different from hardware patents. But programmers are not configuring circuits to take advantage of their physical properties. They are defining the meaning of organizations of data. They implement operations of arithmetic and logic which are applicable to this data based on its meaning.74 The legal view of software is based on a faulty understanding of computer programming.
The functions of software are performed through a combination of defining the meaning of data and giving input to an already implemented algorithm. Meaning is not a physical property of a circuit.75 Giving input to an algorithm is not configuring a machine structure.76 The consequence of the beliefs of the Federal Circuit is to treat as hardware patents what is actually patents on a certain category of expressions of ideas.
This treatment of software patents does not promote innovation because it cannot. Software patents do not actually practice any of the the principles of patent law that theoretically lead to innovation. The patent system cannot function as a property system for software because it is impossible for authors of software to be secure in their own property. Patent disclosure is not being read in practice because there is no reason for software authors to do so and plenty of reasons not to. In addition, the usual costs/benefits analysis of patents is not applicable. The incentive of patents to innovators overlaps with copyrights, FOSS and first mover advantage but their full costs and risks still accrue to the developers and society as a whole.
Software patents harm innovation because they encourage monopolistic rents and litigation.
The cure is simple, the courts should just admit the facts are as they are and apply the law accordingly. They should recognize that computations are expressions of ideas and stop conflating them with applications of ideas.
Not applying this cure will allow the problem to persist. This problem cannot be solved by improving the quality of prior art discovery and analysis. It cannot be solved by curtailing vague or overly broad claims. These improvements are welcome but they don't go to the point. We need to stop allowing patents on the meaning on symbols when they are dressed up as patents on hardware.
An approach based on semiotics would be a better interpretation of the law.77 This approach has the advantage of being neutral relative to technology. It is applicable whenever the claim recites a sign. Anything can be a sign if it is used as a sign. Therefore this approach is not limited to software. It is applicable (and limited) to whenever there is an issue of whether the subject matter of a claim is related to the meaning of a sign.
The semiotics approach avoids terms like "abstract idea" which are hard to define. It doesn't depend on whether the subject matter is mathematical or related to software. It relies on the well understood distinction between an expression and its meaning. It relies on the well understood notion that thoughts in the human mind are abstract ideas. It builds on established principles of law. It relies on the linguistic aspects of mathematics to define a clear boundary between abstract mathematical ideas and their applications which is consistent with Supreme Court precedents.78
There is no need to ask Congress to change the law. It is sufficient for the courts to acknowledge facts and interpret existing law accordingly.
Under this approach claims reciting software will be patentable when they claim a referent which is a patent-eligible invention. An industrial process for curing rubber such as the one in Diehr is patent-eligible. Inventions like remote surgery systems and anti-lock brake systems are patent-eligible when the referent is actually claimed and not merely referred to. Only claims directed to the expression of abstract ideas will be rejected. This is conforming with the theory that innovation is promoted by patents on the application of ideas but not by patents on the ideas themselves.
________________
1
The topics we propose in our response correspond to these sections as follows:
Suggested topic 1: Is computer software properly patentable subject matter?
Topic 1 is the main topic for the whole argument because the whole point of distinguishing between expressions and applications of ideas is to help determine the exact extent where a claim involving software should be patentable. Suggested topics 2, 3 and 4 each cover a particular aspect of this general topic.
Suggested topic 2: Are software patents helping or hurting the US innovation and hence the economy?
Topic 2 is discussed in section D. This topic is numerically listed in second place because of its importance. We discuss it last, in section D, because the flow of ideas works better logically when the reader has first seen the material presented in section A, B and C.
In this section we document how patents on the expressions of ideas in software break the assumptions underlying the operation of the patent system. Three broad categories of assumptions are broken. (1) The patent system cannot work as a property system because there is no way for software authors to clear all rights to their own properties. (2) Disclosure doesn't work because it is ineffective and legally dangerous to read. (3) The standard cost/benefit analysis motivating patents is inapplicable in this context.
None of these three categories of assumptions actually function according to theory. There is no reason to believe the patent system promote innovation because all arguments supporting this conclusion don't apply to how software patents actually work in practice.
Suggested topic 3:
How can software developers help the courts and the USPTO understand how computers actually work so judges' decisions will match technical realities?
Topic 3 is split between sections A and B. Section A explains some principles of computer science while section B identifies errors and how they should be corrected.
The main theme underlying section A is that computers are machines for manipulating symbols which have meaning. Section A defines some terminology, like the vocabulary and concepts of semiotics. This section also explains some principles of computer science such as: (1) What is a mathematical algorithm. (2) How mathematics and algorithms relate to symbols and meaning. (3) How computers use algorithms. (4) What is the stored program architecture. Collectively these principles explain what is the role of expressions and meaning in computer science.
The main theme underlying section B is that computers don't perform their functions solely through their physical properties. They also depend on their semantical properties as is explained in section A. This is contrary to the legal view of software found in case law. The insistence that computer work solely through their physical properties negates the role of semantics in computer programming. This is the source of the conflation between expressions of ideas and application of ideas.
One of the errors is the artificial distinction between a printing process and a computing process which is discussed in our main response. Several other errors of this nature are also discussed in this supplement.
It doesn't help that case law never refers to the descriptions of what is a mathematical algorithm which are found in textbooks of mathematics. This leads to an incorrect distinction between 'mathematical' algorithms and those which are deemed 'non-mathematical'. This also prevents the courts from noticing the role of symbols and meaning in the mathematical foundations of computing.
Suggested topic 4: What is an abstract idea in software and how do expressions of ideas differ from applications of ideas?
Topic 4 is discussed in section C.
We argue that when the referent of symbols is not claimed their meaning is just a thought in the human mind. This suggests that the test for claims directed patent-ineligible abstract ideas should be patterned after the printed matter doctrine. The meaning of symbols must be given no patentable weight unless the referent is actually claimed.
2 Examples of such textbooks are:
Curry, Haskell B., Foundations of Mathematical Logic, Dover Publications, 1977, Revised and corrected reprint from McGraw Hill Book Company, Inc. 1963
Delong, Howard. A Profile of Mathematical Logic. Addison-Wesley Publishing Company. 1970. I use the September 1971 second printing. Reprints of this book are available from Dover Publications.
Epstein, Richard L., Carnielli, Walter A., Computability Computable Functions, Logic and the Foundations of Mathematics, Wadsworth & Brooks/Cole, 1989, pages 63-71.
Kleene, Stephen Cole, Introduction to Metamathematics, D. Van Nostrand Company, 1952. I use the 2009 reprint by Ishi Press International 2009.
Kleene, Stephen Cole, Mathematical Logic, John Wiley & Sons, Inc. New York, 1967, reprint from Dover Publications 2002. pages 223-231.
3 See Rogers, Hartley Jr, Theory of Recursive Functions and Effective Computability, The MIT Press, 1987 pp. 1-2
4 See for instance textbooks on denotational semantics for one method of writing such descriptions. An example of such textbook is Stoy, Joseph E., Denotational Semantics: The Scott-Strachey Approach to Programming Language Theory, MIT Press, First Paperback Edition
5 See Curry supra, pages 1-3 ;
also see Ben-Ari, Mordechai, Mathematical Logic for Computer Science, Second Edition, Springer-Verlag, 2001, for a textbook on mathematical logic as it is applied to computer science.
6 Here are a few places where such descriptions may be found.
Boolos George S., Burgess, John P., Jeffrey, Richard C., Computability and Logic, Fifth Edition, Cambridge University Press, 2007, page 23-25.
Epstein, Richard L., Carnielli, Walter A., Computability Computable Functions, Logic and the Foundations of Mathematics, Wadsworth & Brooks/Cole, 1989, pages 63-71.
Kleene, Stephen Cole, Mathematical Logic, John Wiley & Sons, Inc. New York, 1967, reprint from Dover Publications 2002. pages 223-231.
Kluge, Werner,
Abstract Computing Machines, A Lambda Calculus Perspective
, Springer-Verlag Berlin Heidelberg 2005, pages 11-14.
Minsky, Marvin L.,
Computation, Finite and Infinite Machines
, Prentice-Hall, 1967, pages 103-111
Stoltenberg-Hansen, Viggo, Lindström, Ingrid, Griffor, Edward R.,
Mathematical Theory of Domains
, Cambridge University Press, 1994, pages 224-225.
7 See Stoltenberg-Hansen and al., supra, page 224.
8 See Stoltenberg-Hansen and al., supra, page 224.
9 See Boolos and al. supra, page 23.
10 See Boolos and al. supra, page 187.
11 See Epstein and al., supra, pages 65-66, quoting from Hermes, Enumerability, Decidability, Computability. 2nd ed., Springer Verlag 1969. "[W]e must be able to express the instructions for the execution of the process in a finitely long text." See also Stoltenberg-Hansen, Lindström and Griffor, supra, page 224. "[An algorithm] is a method or procedure which can be described in a finite way (a finite set of instructions)"
12 See Boolos and al. supra, pages 23.
13 See Stoltenberg-Hansen, Lindström and Griffor, supra, page 224. "[An algorithm] can be followed by someone or something to yield a computation solving each problem in [a class of problems]."
14 See Boolos and al. supra, pages 23-24.
15 See Kluge, supra, page 12.
16 See Stoltenberg-Hansen and al., supra, page 225.
17 This is Turing machines, general recursive functions and λ-calculus.
18 See Kluge, supra, page 12
19 See Kleene, supra, page 223.
20 See Epstein and al., supra, page 70.
21 A model of computation is a class of syntactic manipulations of symbols defined in terms of the permissible operations. Examples of models of computations are Turing-machines, λ-calculus and general recursive functions.
22 For a discussion of how problems are represented syntactically using symbols, see Greenlaw, Raymond, Hoover, H. James, Fundamentals of the Theory of Computation, Principles and Practice, Morgan Kaufmann Publishers, 1998, Chapter 2.
23 This is used during debugging. Programmers verify programs work as intended by reading the data stored in the computer memory. They interpret this information according to its logical data type to determine if the program implement the operations of arithmetic and logic that solves the problem.
24 See Poernomo, Iman Hafiz, Crossley, John Newsome, Wirsing, Martin, Adapting Proofs-as-Program, The Curry-Howard Protocol, Springer 2005. This thesis is presented in chapters 4, 5 and 6.
25 See Ben-Ari, supra, chapter 7 and 8 for a discussion of SLD-resolution.
26
See Kluge,
supra,
for a book dedicated to several implementations of normal order
β
-reduction. It should be noted that normal order
β
-reduction is a universal algorithm which modifies its program as the computation progresses. It cannot be assumed the program is always unchanged by the computation as is usually (but not always) the norm in imperative programming.
27 This is a simplified explanation for readability. Here is how Hamacher, V. Carl, Vranesic, Zvonko G., Zaky. Safwat G., describes the hardware implementation of an instruction cycle. See Computer organization, Fifth Edition, McGraw-Hill Inc. 2002 p. 43 (emphasis in the original)
Let us consider how this program is executed. The processor contains a register called the program counter (PC) which holds the address of the instruction to be executed next. To begin executing a program, the address of its first instruction (i in our example) must be placed into the PC. Then, the processor control circuits use the information in the PC to fetch and execute instructions, one at a time, in the order of increasing addresses. This is called straight-line sequencing. During the execution of each instruction, the PC is incremented by 4 to point to the next instruction. Thus, after the Move instruction at location i + 8 is executed the PC contains the value i + 12 which is the address of the first instruction of the next program segment.
Executing a given instruction is a two-phase procedure. In the first phase, called instruction fetch, the instruction is fetched from the memory location whose address is in the PC. This instruction is placed in the instruction register (IR) of the processor. At the start of the second phase, called instruction execute, the instruction in IR is examined to determine which operation to be performed. The specified operation is then performed by the processor. This often involve fetching operands from the memory or from processor registers, performing an arithmetic or logic operation, and storing the result in the destination location. At some point during this two-phase procedure, the contents of the PC are advanced to point at the next instruction. When the execute phase of an instruction is completed, the PC contains the address of the next instruction, and a new instruction fetch phase can begin.
28 A suitable analogy may be travel directions. These instructions don't drive the car. They are input given to the driver.
29 See section A.3, supra. Section A.2 explains the relationship between algorithms, formulas and equations. These two sections explain the mathematical meaning of all terms which have troubled the Federal Circuit in AT&T Corporation.
30 See Milner, Robin, Tofte, Mads, Harper, Robert, MacQueen, David, The Definition of Standard ML (Revised) , The MIT Press, 1997, for the official definition of the Standard ML language. See also Reppy, John H., Concurrent Programming in ML, Cambridge University Press, First published 1999, Digitally printed version (with corrections) 2007, appendix B, for the official definition of the Concurrent ML extensions.
31 See section A.3 supra.
32 Cybersource Corporation vs Retail Decisions, Inc. sounds like a possible example of this argument. They write "That purely mental processes can be unpatentable, even when performed by a computer, was precisely the holding of the Supreme Court in Gottschalk v. Benson." And then they continue writing "This is entirely unlike cases where, as a practical matter, the use of a computer is required to perform the claimed method." Benson is the case which established the mathematical algorithm exception. To the extent that ordinary logic is applicable here, one may conclude the Federal Circuit in Cybersource said the mathematical algorithm exception is not applicable when the use of a computer is required as a practical matter to perform the claimed method. Mathematicians have deliberately decided to ignore this kind of distinction when they defined their notion of algorithm.
33 See section A.4 supra.
34 This is unless we count artificial intelligence programs such as IBM's Watson as being able to relate the syntax of human language with its meaning. No matter how we look at this issue, there is no factual difference between a printing press and a computer instruction cycle. If we consider computers as unable to understand meaning they are no better than printing presses. But if they are able to understand meaning printed information is not intelligible only by a human being. Either way the guidance offered by Lowry doesn't apply to the facts.
35 See section A.4 supra
36 An alternative version of the change to the machine structure argument has been stated in WMS Gaming vs International Game technology:
The instructions of the software program that carry out the algorithm electrically change the general purpose computer by creating electrical paths within the device. These electrical paths create a special purpose machine for carrying out the particular algorithm.[3]
______________
[Footnote 3]: A microprocessor contains a myriad of interconnected transistors that operate as electronic switches. See Neil Randall, Dissecting the Heart of Your Computer, PC Magazine, June 9, 1998, at 254-55. The instructions of the software program cause the switches to either open or close. See id. The opening and closing of the interconnected switches creates electrical paths in the microprocessor that cause it to perform the desired function of the instructions that carry out the algorithm. See id.
This alternative explanation is immediately refuted because it is manifestly false. A stored program computer is programmed by storing the instructions in main memory. This action doesn't create electrical paths because main memory doesn't work in this manner. Main memory is a component that merely records information. On modern DRAM technology this information is electric charges stored in capacitors. No transistors are opened and closed to create electric paths in the microprocessor when these electric charges are stored.
Programs are not stored in the microprocessor mentioned in the footnote because this component is not main memory. The activity of the transistors turning on and off in the microprocessor is the execution of the program. Programming a computer and executing a program are two separate actions. It is an error to conflate them as the court do in WMS Gaming.
The instructions that could be executed by a microprocessor are very elementary. A complete algorithm typically requires a large number of these rudimentary instructions. Complete programs require thousands or even millions of instructions. On the other hand a microprocessor typically executes the instructions one by one. In some microprocessors gains of speed are achieved by executing a very small quantity of instructions in parallel when it is feasible to do so. Microprocessor execute large number of instructions by executing on them in successive cycles, one (or a few) instruction(s) per cycle. The transistors turning on and off are the execution of this small number of instructions and different electrical paths are created in each cycle. No electric paths for carrying out a particular algorithm is created because the number of instructions which are executed in a single cycle is too small.
See section A.5 supra for a discussion of the instruction cycle.
37 In mathematics this partial application of the parameters of a mathematical function is called currying.
38 These function are not special cases of multiplication. We can double a number by adding it with itself. This shows that doubling is a concept independent from multiplication because we can implement it without multiplying. Similarly we can triple a number by adding it with itself twice. Adding the number with itself three times quadruple the number.
39 Here is another way to illustrate the relationship between meaning and machine. Please recall the claim about a printing press configured to make marks of ink of paper telling the story of hobbits traveling in faraway countries to destroy an evil anvil. It was mentions in section B.3 supra.
We may argue that a configured printing press is different from an unconfigured printing press. Different books are different articles of manufacture. The marks of ink on paper will not be arranged in the same manner. Therefore printing presses configured for different books will perform different functions because they don't manufacture the same article. This means a printing press configured to print a book is a different machine than a printing press without the configuration. One may print the stated book while the other can't. Also, the configured printing press is physically different from the unconfigured one because some of its elements are differently arranged.
This argument repeats the typical justifications of the doctrine that programming a computer makes a machine different from the unprogrammed computer. The correspondence is complete when we consider that a printing press may be controlled by an embedded programmed microprocessor and a computer may be connected to a printer. In section B.3 we argued there are no factual differences between a printing press and a computer that would justify a applying the printed matter doctrine to a configured printing press but not to a programmed computer. Now we make the same observation about the "makes a different machine" doctrine.
While we argue the printed matter doctrine should apply to both types of devices, we argue the "makes a different machine" doctrine should apply to neither.
40 In some cases the configuration can be made permanent by storing it in memory types such as ROM that can't be overwritten. However typical software patents are not limited to this type of memory. They will read on implementations using the more commonly used writable memory.
41 Remember that it is not possible to define this process in terms of the meaning of the data.
42 Without such an argument his position would immediately be refuted by the observation that main memory changes up to billions of times per second.
43 Let's consider, for example, what happens when we store instructions for a x86 CPU on a SPARC workstation. The SPARC uses a different instruction set than the x86. A program for a x86 computer does not normally run on a SPARC workstation. But a SPARC can execute the Bochs program which is a software version of the x86 instruction cycle. If this program is used the x86 program will run on a SPARC. This shows that instructions by themselves are just a series of numbers in memory. They don't impart functionality unless and until they are given as input to an algorithm which is the instruction cycle.
44 Please remember that several programing languages use a software universal algorithm. They don't directly use the computer native instruction cycle. See section A.5 supra.
45 The extreme case occurs with self-modifying programs. In a stored program computer all data in memory may be modified as the program is executed. Programmers may arrange their programs so that they are modified in memory as they are executed. Then the alleged "machine configuration" doesn't stay in place long enough to perform all the steps that are necessary to infringe on the patent claim. A simple way to achieve this result is to use a programming language with relies on a variant of normal order β-reduction as its universal algorithm. (See section A.5 supra.) This particular category of universal algorithms constantly modifies its program as it executes. This is done automatically by the language run-time system without any action of the part of the programmer other than his decision to program in this language.
46 See section B.2 supra.
47 An example of a symbol is a letter in the common Latin alphabet. A letter may be a mark of in on paper, a carving in stone, the shape of a neon sign, an arrangement of pixels on the screen. A letter come in different shapes depending on typefaces. These are different physical objects separate from the abstraction called a letter. This concept of 'symbol' as an abstraction separate from its representation is explicitly acknowledged in mathematical logic and computation theory. See for instance Curry, supra, pages 15-16.
In the theory presented here, one may conceive such assumptions as entering in certain abstractions. The first of these is involved in the use of such terms as 'symbol' and 'expression'; these denote, not individual marks on paper or the blackboard--which are called inscriptions--but classes of such inscriptions which are "equiform." Thus the same expressions may have several "occurrences."
48 See section A.1. The approach suggested here has been proposed in Collins, Kevin Emerson, Semiotics 101: Taking the Printed Matter Doctrine Seriously (February 28, 2009). Indiana Law Journal, Vol. 85, p. 1379, 2010. Available at SSRN: http://ssrn.com/abstract=1351066. We don't agree with everything Collins say because he did not recognize the errors we have mentioned in section B. We believe that once these errors are corrected his approach is correct.
49 See section A.4 supra.
50 This is the thesis of Kevin Emerson Collins in his article quoted supra.
51 See the criteria of "precise definition" for the mathematical notion of algorithm in section A.3 supra.
52 See section B.2 supra.
53 See sections B.1 and B.2, supra.
54 See sections B.3 and footnote 39, supra.
55 See section B.4, supra.
56 See sections B.5 and B.6, supra.
57 See section A.4, supra.
58 See Lemley, Mark A., Software Patents and the Return of Functional Claiming (July 25, 2012). Stanford Public Law Working Paper No. 2117302. Available at SSRN: http://ssrn.com/abstract=2117302 or http://dx.doi.org/10.2139/ssrn.2117302 pages 24-25.
59 See Mulligan, Christina and Lee, Timothy B., Scaling the Patent System (March 6, 2012). NYU Annual Survey of American Law, Forthcoming. Available at SSRN: http://ssrn.com/abstract_id=2016968.
60 See Mulligan and Lee, supra, pp. 16-17
61 See Mulligan and Lee, supra, p. 7.
62 See Mulligan and Lee, supra, p. 6.
In the real world, lawyers frequently cannot state for certain whether a given activity actually infringes a particular patent. In this paper, we will largely set this issue to the side and assume counterfactually that lawyers can always determine whether a particular activity infringes a particular patent in a reasonable amount of time. For further reading on the challenges of claim construction and determining the scope of patents, see Jeanne Fromer, Claiming Intellectual Property, 76 U. CHI. L. REV. 719 (2009), Michael Risch, The Failure of Public Notice in Patent Prosecution, 21 HARV. J. L. & TECH. 179 (2007); Christopher A. Cotropia, Patent Claim Interpretation Methodologies and their Claim Scope Paradigms, 47 WM. & MARY L. REV 49 (2005); Christopher A. Cotropia, Patent Claim Interpretation and Information Costs, 9 LEWIS & CLARK L. REV. 57 (2005).
63 See Lemley, Mark A., Ignoring Patents (July 3, 2007). Stanford Public Law Working Paper No. 999961; Michigan State Law Review, Vol. 2008, No. 19, 2008. Available at SSRN: http://ssrn.com/abstract=999961 or http://dx.doi.org/10.2139/ssrn.999961 pages 19-21.
64 See Mulligan and Lee, supra, pp 2-4.
65 A description of what is free software is maintained by the Free Software Foundation. The Open Source Initiative maintains the definition of open source software.
66 The Free Software Foundation maintains a list of licenses which are accepted for free software development. The Open Source Initiative also maintains their list of licenses for open source software.
67 The most famous example is the Linux operating system kernel. It is at the core of several operating systems such as GNU/Linux and Android. We may also mention the Perl and Python programming languages, the Coq proof assistant, web browsers such as Firefox and Chrome and also the Apache web server. This list far from exhaustive.
68 See RFC 2026 for the current version of the RFC development process. RFC 2555 is an historic account describing how the RFC process has been used to invent and disclose the core Internet protocols.
69 An example of a reference implementation is found in RFC 1321 Appendix A. Reference implementations may also be incorporated by reference. For example RFC 5905 includes the reference "This document includes material from [ref9], which contains flow charts and equations unsuited for RFC format. There is much additional information in [ref7], including an extensive technical analysis and performance assessment of the protocol and algorithms in this document. The reference implementation is available at www.ntp.org." This same RFC 5905 also includes a skeleton program with code segments in appendix A.
70 See Lemley, Mark A., Ignoring Patents (July 3, 2007). Stanford Public Law Working Paper No. 999961; Michigan State Law Review, Vol. 2008, No. 19, 2008. pages 21-22.
Available at SSRN:
http://ssrn.com/abstract=999961
or
http://dx.doi.org/10.2139/ssrn.999961
71 Benjamin Roin, Note, The Disclosure Function of the Patent System (Or Lack Thereof), 118 HARV. L. REV. 2007 (2005) (noting that the patent system doesn't achieve this disclosure goal). Available at: http://hlr.rubystudio.com/issues/118/april05/Note_3857.php
72 Eric Goldman explains this first mover advantage in term of the soft life-cycle of software. (See Goldman, Eric, Fixing Software Patents (January 1, 2013). Forbes Tertium Quid Blog, November 28, December 11 and December 12, 2012; Santa Clara Univ. Legal Studies Research Paper No. 01-13. Available at SSRN: http://ssrn.com/abstract=2199180 page 2)
Software innovators can recoup some of their R&D investments from the de facto marketplace exclusivity associated with being the first mover. An example: assume that a particular software innovation has a two-year commercial lifecycle and it takes competitors 6 months to bring a matching product to market. In a situation like this, the first mover gets 1/4 of the maximum useful exclusivity period simply by being first to market. In some situations, the exclusivity period provided by the first mover advantage is more than enough to motivate software R&D without any patent protection.
73 See section B generally, especially the quote from In re Noll in section B.6, supra..
74 See section A.3 and A.4, supra.
75 See section B generally, especially sections B.3, B.4, B.5 and B.6, supra.
76 See section B.5, supra.
77 This is the approach we have described in section C.2, supra.
78 See section B.4, supra.
|
|
|
|
| Authored by: lnuss on Sunday, March 10 2013 @ 09:20 PM EDT |
...
---
Larry N.[ Reply to This | # ]
|
- by --> be - Authored by: lnuss on Sunday, March 10 2013 @ 09:21 PM EDT
- Two incorrect uses of asterisks - Authored by: bugstomper on Sunday, March 10 2013 @ 09:57 PM EDT
- "stop allowing patents on the meaning on symbols" meaning on -> meaning of [N/T] - Authored by: bugstomper on Sunday, March 10 2013 @ 10:02 PM EDT
- referred to -> referenced - Authored by: Anonymous on Sunday, March 10 2013 @ 10:38 PM EDT
- Doe => Do - Authored by: Anonymous on Sunday, March 10 2013 @ 10:49 PM EDT
- Delete 'it' - Authored by: Anonymous on Sunday, March 10 2013 @ 10:53 PM EDT
- an hypothetical -> a hypothetical - Authored by: Anonymous on Sunday, March 10 2013 @ 10:58 PM EDT
- Wording - Authored by: Anonymous on Sunday, March 10 2013 @ 11:02 PM EDT
- Wording - Authored by: PolR on Sunday, March 10 2013 @ 11:07 PM EDT
- Tolkien's Lord of the Ring. - Authored by: Anonymous on Sunday, March 10 2013 @ 11:38 PM EDT
- λ-calculus - Authored by: Arthur Marsh on Sunday, March 10 2013 @ 11:54 PM EDT
- It is well know -> It is well known - Authored by: IANALitj on Monday, March 11 2013 @ 12:00 AM EDT
- .. majority of algorithms can carried.. - Authored by: Anonymous on Monday, March 11 2013 @ 03:20 AM EDT
- developer -> developers - Authored by: Anonymous on Monday, March 11 2013 @ 06:05 AM EDT
- The meaning of this formula is a is a law of nature - Authored by: tiger99 on Monday, March 11 2013 @ 06:34 AM EDT
- Corrections Thread Here...mush work - Authored by: Anonymous on Monday, March 11 2013 @ 06:52 AM EDT
- pointing our that -> pointing out that (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 07:17 AM EDT
- the same authors explains -> the same authors explain (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 07:21 AM EDT
- This burden typically vary -> This burden typically varies (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 07:26 AM EDT
- carryout -> carry out - Authored by: indyandy on Monday, March 11 2013 @ 07:32 AM EDT
- Boolos and al. -> Boolos et al. (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 07:37 AM EDT
- the point of view syntactic manipulations -> the point of view of syntactic manipulations - Authored by: indyandy on Monday, March 11 2013 @ 07:55 AM EDT
- programmer fails to to find -> programmer fails to find (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 07:57 AM EDT
- They can be turned into algorithm -> They can be turned into an algorithm - Authored by: indyandy on Monday, March 11 2013 @ 08:06 AM EDT
- data types corresponds to -> data types correspond to (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 08:09 AM EDT
- When the algorithm process the data -> When the algorithm processes the data (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 08:14 AM EDT
- a printed --> a printer - Authored by: Ding-Batty on Monday, March 11 2013 @ 08:20 AM EDT
- Universal algorithms makes possible -> Universal algorithms make it possible - Authored by: indyandy on Monday, March 11 2013 @ 08:31 AM EDT
- general purpose computer built -> general purpose computer is built - Authored by: indyandy on Monday, March 11 2013 @ 08:35 AM EDT
- every computation in is a -> every computation is a (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 08:37 AM EDT
- This instruction themselves -> These instructions themselves (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 08:42 AM EDT
- Each error either disregard or deny the role -> Each error either disregards or denies the role - Authored by: indyandy on Monday, March 11 2013 @ 08:46 AM EDT
- are ->which are - Authored by: feldegast on Monday, March 11 2013 @ 08:48 AM EDT
- exists -> exist - Authored by: feldegast on Monday, March 11 2013 @ 08:54 AM EDT
- Doe you see a difference -> Do you see a difference (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 09:19 AM EDT
- for the same of -> for the sake of - Authored by: indyandy on Monday, March 11 2013 @ 09:23 AM EDT
- calculation and and application -> calculation and application (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 09:25 AM EDT
- The issue of meaning arise -> The issue of meaning arises (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 09:32 AM EDT
- computer write symbols -> computer writes symbols - Authored by: indyandy on Monday, March 11 2013 @ 09:40 AM EDT
- everyone understand and acknowledge -> everyone understands and acknowledges (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 09:49 AM EDT
- laws of physics follows the -> laws of physics follow the (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 09:58 AM EDT
- But when its is -> But when it is (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 10:00 AM EDT
- arguments follows from -> arguments follow from (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 10:06 AM EDT
- computers are build according -> computers are built according (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 10:08 AM EDT
- grammatical - Authored by: ukjaybrat on Monday, March 11 2013 @ 10:10 AM EDT
- number -> numbers multiply -> multiplies the same -> some (see comment) - Authored by: indyandy on Monday, March 11 2013 @ 10:19 AM EDT
- missing word? - Authored by: swmcd on Monday, March 11 2013 @ 10:29 AM EDT
- typo - Authored by: swmcd on Monday, March 11 2013 @ 10:32 AM EDT
- In-between needs two objects - Authored by: swmcd on Monday, March 11 2013 @ 10:36 AM EDT
- one of its argument in -> one of its arguments in (Also see comment) - Authored by: indyandy on Monday, March 11 2013 @ 10:36 AM EDT
- physical properties of electrical circuit. -> physical properties of electrical circuits. (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 10:41 AM EDT
- the computer will functions -> the computer will function (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 10:44 AM EDT
- ignores -> ignore / size -> sizes (see comment) - Authored by: indyandy on Monday, March 11 2013 @ 10:50 AM EDT
- symbols -> symbol / is -> and is (see comment) - Authored by: indyandy on Monday, March 11 2013 @ 10:54 AM EDT
- long -> if (?????? see comment) - Authored by: indyandy on Monday, March 11 2013 @ 10:58 AM EDT
- by electronic meas -> by electronic means (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 11:01 AM EDT
- Corrections Thread Here... - Authored by: Anonymous on Monday, March 11 2013 @ 11:04 AM EDT
- In semiotics term the -> In semiotics terms the (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 11:04 AM EDT
- is just to great -> is just too great (N/T) - Authored by: indyandy on Monday, March 11 2013 @ 11:19 AM EDT
- firm -> firms / infringing -> be infringing (see comment) - Authored by: indyandy on Monday, March 11 2013 @ 11:26 AM EDT
- authors wish to be active participant -> authors wish to be active participants - Authored by: indyandy on Monday, March 11 2013 @ 11:32 AM EDT
- can -> can't (see comment) - Authored by: indyandy on Monday, March 11 2013 @ 11:41 AM EDT
- model -> models / where -> when (see comment) - Authored by: indyandy on Monday, March 11 2013 @ 11:46 AM EDT
- system promote innovation -> system promotes innovation N/T - Authored by: indyandy on Monday, March 11 2013 @ 12:09 PM EDT
- But they can verify they won't infringe on the rights of -- can -> can't - Authored by: Liquor A. on Monday, March 11 2013 @ 12:12 PM EDT
- typo - Authored by: swmcd on Monday, March 11 2013 @ 12:13 PM EDT
- computer work solely -> computers work solely - Authored by: indyandy on Monday, March 11 2013 @ 12:14 PM EDT
- mathematical impossibility -> practical impossibility - Authored by: nsomos on Monday, March 11 2013 @ 12:21 PM EDT
- Apologies for duplicates... - Authored by: indyandy on Monday, March 11 2013 @ 12:28 PM EDT
- typo - Authored by: swmcd on Monday, March 11 2013 @ 12:39 PM EDT
- typo - Authored by: swmcd on Monday, March 11 2013 @ 01:09 PM EDT
- Where is footnote 1? - Authored by: swmcd on Monday, March 11 2013 @ 01:11 PM EDT
- Corrections Thread Here... - Authored by: Anonymous on Monday, March 11 2013 @ 02:00 PM EDT
- three - Authored by: Anonymous on Monday, March 11 2013 @ 05:19 PM EDT
- in three ways --> in four ways? - Authored by: Anonymous on Monday, March 11 2013 @ 05:43 PM EDT
| |
| Authored by: lnuss on Sunday, March 10 2013 @ 09:22 PM EDT |
...
---
Larry N.[ Reply to This | # ]
|
- Speed cameras a scam says Judge ... - Authored by: Anonymous on Monday, March 11 2013 @ 08:18 AM EDT
- Interesting - Authored by: Anonymous on Monday, March 11 2013 @ 09:37 AM EDT
- Interesting - Authored by: Anonymous on Monday, March 11 2013 @ 09:40 AM EDT
- Interesting twist on the subject - Authored by: Anonymous on Monday, March 11 2013 @ 02:04 PM EDT
- Interesting - Authored by: Anonymous on Monday, March 11 2013 @ 09:36 PM EDT
- Interesting - Authored by: Anonymous on Tuesday, March 12 2013 @ 05:23 AM EDT
- Interesting - Authored by: Anonymous on Tuesday, March 12 2013 @ 12:02 AM EDT
- Interesting - Authored by: Anonymous on Monday, March 11 2013 @ 02:24 PM EDT
- Speed cameras a scam says Judge ... - Authored by: ukjaybrat on Monday, March 11 2013 @ 10:34 AM EDT
- Speed cameras a scam says Judge ... - Authored by: Anonymous on Monday, March 11 2013 @ 12:17 PM EDT
- How about a combination? - Authored by: Anonymous on Tuesday, March 12 2013 @ 04:40 PM EDT
- Not sure this is off-topic - Authored by: Anonymous on Monday, March 11 2013 @ 08:56 AM EDT
- I have a few ones and zeros that I do not need anymore . - Authored by: Anonymous on Monday, March 11 2013 @ 09:04 AM EDT
- a new arena for patent wars - Authored by: ukjaybrat on Monday, March 11 2013 @ 10:46 AM EDT
- Not sure this is off-topic - Authored by: DannyB on Monday, March 11 2013 @ 11:34 AM EDT
- Ha, ha, ha, ha, ha, ha, ha, ha, ha, ha, ha... - Authored by: albert on Monday, March 11 2013 @ 03:36 PM EDT
- The publishers will not like this either. - Authored by: Anonymous on Tuesday, March 12 2013 @ 04:45 PM EDT
- interesting - 2005 iphone - Authored by: designerfx on Monday, March 11 2013 @ 09:54 AM EDT
- CISPA, the Privacy-Invading Cybersecurity Spying Bill, is Back in Congress - Authored by: Anonymous on Monday, March 11 2013 @ 06:49 PM EDT
- Deep Dive Analysis: Brett Gibbs Gets His Day In Court -- But Prenda Law Is The Star - Authored by: artp on Tuesday, March 12 2013 @ 12:00 AM EDT
- Little Green Men Miss Arthur C Clarke - Authored by: Anonymous on Tuesday, March 12 2013 @ 03:32 AM EDT
| |
| Authored by: lnuss on Sunday, March 10 2013 @ 09:23 PM EDT |
...
---
Larry N.[ Reply to This | # ]
|
- There Was That Whole Internet Thing, Too - Authored by: Anonymous on Monday, March 11 2013 @ 01:20 AM EDT
- Low-numbered ports and root access? ... - Authored by: Anonymous on Monday, March 11 2013 @ 08:30 AM EDT
- Facebook reveals secrets - Authored by: Anonymous on Monday, March 11 2013 @ 06:10 PM EDT
- MPEG LA and Google Settle: What Does it Mean? - Authored by: Tim on Monday, March 11 2013 @ 08:46 PM EDT
- Judge “came in like a tornado” at Prenda Law lawyers - Authored by: Anonymous on Monday, March 11 2013 @ 11:41 PM EDT
- ..angry judge at Pretenda Law - Authored by: arnt on Tuesday, March 12 2013 @ 12:10 AM EDT
- ..Brett Gibbs Gets His Day In Court — But Prenda Law Is The Star - Authored by: arnt on Tuesday, March 12 2013 @ 12:21 AM EDT
- Clapper v. Amnesty International: What does "certainly impending" mean? - Authored by: Anonymous on Tuesday, March 12 2013 @ 02:03 AM EDT
- amusing presence in the courtroom - Authored by: IANALitj on Tuesday, March 12 2013 @ 02:34 AM EDT
| |
| Authored by: lnuss on Sunday, March 10 2013 @ 09:24 PM EDT |
...
---
Larry N.[ Reply to This | # ]
|
| |
| Authored by: lnuss on Sunday, March 10 2013 @ 09:41 PM EDT |
I'll second Timinski's comment -- these four suggestions are extremely well
done, and easy to follow.
---
Larry N.[ Reply to This | # ]
|
| |
| Authored by: Anonymous on Sunday, March 10 2013 @ 09:47 PM EDT |
Patenting a business practice because it is implimented on a computer
is wrong. Huntington Bank has a patent on providing 24 hours grace on
overdraft and sending an email notice on fund shortage. This is a
business practice. The same thing can be done by phone.
The fat 32bit file system is simply a set of rules for writing bits on a disk.
The only signifigance is the pattern is recognized by another computer.
This should not be patentable.
These are two examples of problems the questions should expose.
[ Reply to This | # ]
|
| |
| Authored by: BJ on Sunday, March 10 2013 @ 10:28 PM EDT |
Although I hesitate to give input since not a US citizen.
bjd
[ Reply to This | # ]
|
| |
| Authored by: swmcd on Sunday, March 10 2013 @ 10:54 PM EDT |
This text
There are roughly 634,000 firms in the United States with
20 or more employees. While not all of these firms produce software, many of the
1.7 million firms with 5 to 19 employees do.
seems confused. It
distinguishes firms by size, but the point of the distinction is unclear. Many
of the firms with 20 or more employees also produce software.[ Reply to This | # ]
|
| |
| Authored by: swmcd on Sunday, March 10 2013 @ 11:11 PM EDT |
The explanation for this topic is too long, too repetitive, and too
abstract.
The goal of the submission is just to get the topics in front of the
USPTO.
The supplement can go into detail.
I would condense it to
The
current interpretation of patent law is plagued with what developers view as
erroneous conceptions of how computers work. Other than the current USPTO
request for input, developers feel shut out of decisions, and yet they are the
very ones who understand what software is and how it does what it
does.
Textbooks describe in detail what mathematical algorithms are, but no
one seems to understand or to reference these sources. Instead, we see courts
using standard dictionaries, and the result is confusion about what algorithms
are. An unrealistic distinction between so-called mathematical algorithms and
those that purportedly are not mathematical has been the result. Since this
impacts the controversy of when a computer-implemented invention is directed to
a patent-ineligible abstract idea, it's a serious omission.
Second, it seems
some, including some courts, believe the functions of software are performed
through the physical properties of electrical circuits, incorrectly treating the
computer as a device which operates solely through the laws of physics. This
approach is factually and technically incorrect because not everything in
software functions through the laws of physics. Bits are symbols, and they have
meanings. The meaning of bits is essential to performing the functions of
software. The capability of bits to convey meaning is not a physical property of
the computer.
Software developers don't write software by working with the
physical properties of circuits. Developers define the meaning of data and
implement operations of arithmetic and logic that apply to the meaning. They
debug software by reading the meaning of the data stored in the computer and
verifying whether the correct operations are performed. The aspects of software
related to meaning cannot be explained solely in terms of the physical
properties of the computer.
This erroneous physical view of the computer is
the basis of an oft-stated argument. Some claim that software alters the
computer it runs on. This is used to justify the view that software patents are
actually a subcategory of hardware patents. But to demonstrate what is wrong
with that argument, let's compare a printing press with a computer.
Imagine
a claim on a printing press configured to print a specific book, say Tolkien's
Lord of the Rings. This is a claim on a machine which operates according
to the laws of physics. Printing is a physical process for laying ink on paper.
It functions without the intervention of a human mind. But still this process
involves the meaning of a book. The claim is infringed only if the book has the
recited meaning.
Imagine now that every time a printing press prints a new
book, you could patent that printing press as a new machine because it printed a
new book. That is exactly what patent law does with software, purporting to
create a new machine because new software running on the computer supposedly
creates a new machine. And yet the computer, like a printing press, can run any
software at all that you can devise, just as a printing press can print any book
you write.
No one would allow a patent on a previously existing printing
press just because it is now configured to print a new novel. Yet that is
exactly what is allowed with software.
The consequence is a proliferation of
patents on the expressions of ideas.
[ Reply to This | # ]
|
| |
| Authored by: Anonymous on Sunday, March 10 2013 @ 11:14 PM EDT |
There is not a single person in the Judiciary or at the patent office with the
intelligence to understand a word of it. They will pretend to read it, shake
their heads, and ask the big corporations that bribe them what they should do.
[ Reply to This | # ]
|
| |
| Authored by: BJ on Sunday, March 10 2013 @ 11:26 PM EDT |
"The capability of bits to convey meaning is not a physical property of the
computer."
That capability lies wholly outside of the computer, I'd venture.
bjd
[ Reply to This | # ]
|
| |
| Authored by: swmcd on Sunday, March 10 2013 @ 11:32 PM EDT |
| Currently the distinction between the two, function and algorithm, is not
made correctly in software patents. [ Reply to This | # ]
|
| |
| Authored by: swmcd on Sunday, March 10 2013 @ 11:36 PM EDT |
| These sign-vehicles are turned into signs by semiosis when a human interpreter
reads meanings into them. [ Reply to This | # ]
|
| |
| Authored by: swmcd on Sunday, March 10 2013 @ 11:46 PM EDT |
Here are the is a collection of requirements
for a procedure to be an algorithm[ Reply to This | # ]
|
| |
| Authored by: swmcd on Sunday, March 10 2013 @ 11:50 PM EDT |
| The requirements of finite description and precise definition [ Reply to This | # ]
|
| |
| Authored by: swmcd on Sunday, March 10 2013 @ 11:51 PM EDT |
This burden typically varyies according to the
size of the inputs.[ Reply to This | # ]
|
| |
| Authored by: rsteinmetz70112 on Monday, March 11 2013 @ 12:00 AM EDT |
I have begun wondering whether a large part of the problem is the legal practice
of patent law where everyone agrees that the patent bar seek to enlarge the
scope of a patent.
Suppose the courts were to adopt a common principle of "Contra
Proferentem" which generally holds that ambiguous terms are construed
against the drafter. This would encourage patent applicants to define their
inventions precisely.
Expansion of earlier definitions to apply to later technologies which should be
improvement patents for a new use of an existing technology should not be
allowed.
---
Rsteinmetz - IANAL therefore my opinions are illegal.
"I could be wrong now, but I don't think so."
Randy Newman - The Title Theme from Monk
[ Reply to This | # ]
|
| |
| Authored by: swmcd on Monday, March 11 2013 @ 12:13 AM EDT |
Each error either disregards or
denyies the role of symbols ...[ Reply to This | # ]
|
| |
| Authored by: swmcd on Monday, March 11 2013 @ 12:16 AM EDT |
| Historically the courts have had problems understanding the
term "mathematical algorithm".
OR
Historically the courts have had
problemdifficulty understanding the term
"mathematical algorithm". [ Reply to This | # ]
|
| |
| Authored by: swmcd on Monday, March 11 2013 @ 12:24 AM EDT |
| 2. The vast majority of algorithms can be carried out in
practice for smaller inputs and are impractical for larger inputs. [ Reply to This | # ]
|
| |
| Authored by: swmcd on Monday, March 11 2013 @ 12:27 AM EDT |
the burden of carrying out the steps onof an
algorithm[ Reply to This | # ]
|
| |
| Authored by: swmcd on Monday, March 11 2013 @ 12:30 AM EDT |
| There are a few exceptions, but typical
algorithms...
OR
There are fewsome
exceptions, but typical algorithms...
[ Reply to This | # ]
|
| |
| Authored by: swmcd on Monday, March 11 2013 @ 12:36 AM EDT |
Consider omitting these two paragraphs
We may compare algorithms
with legal arguments. ...
Computations are mathematical written utterances
...
They may bring more confusion that clarity.
A particular
concern is that they encourage lawyers to think of algorithms in terms of their
own legal documents. While this is a possibly interesting comparison, right now
what we are trying to do is get lawyers to understand and accept the
mathematical definition of an algorithm, which is a very different thing. [ Reply to This | # ]
|
| |
| Authored by: swmcd on Monday, March 11 2013 @ 12:38 AM EDT |
There is no difference in a computer structure between doing a calculation for
the samesake of knowing the numerical answer
and doing a calculation because the numbers mean something in the real world.[ Reply to This | # ]
|
| |
| Authored by: swmcd on Monday, March 11 2013 @ 12:45 AM EDT |
The transition between these two sentences needs to be more
clear
If we use a computer to compute the trajectories of
satellites in orbit the satellite and their trajectories are not computer parts.
There are only instructions for manipulating numbers.
Or just omit
the two sentences. I don't think they are essential to the flow of the argument.[ Reply to This | # ]
|
| |
| Authored by: swmcd on Monday, March 11 2013 @ 12:46 AM EDT |
DoeDo you see a difference in the calculator
circuit?[ Reply to This | # ]
|
| |
| Authored by: swmcd on Monday, March 11 2013 @ 12:48 AM EDT |
Second, the difference between a pure mathematical calculation
and and application of mathematics[ Reply to This | # ]
|
| |
| Authored by: swmcd on Monday, March 11 2013 @ 12:51 AM EDT |
A computer may be connected to a printedr.[ Reply to This | # ]
|
| |
| Authored by: swmcd on Monday, March 11 2013 @ 12:53 AM EDT |
| transform any algorithm into non-executable data [ Reply to This | # ]
|
| |
| Authored by: swmcd on Monday, March 11 2013 @ 12:56 AM EDT |
| The issue of meaning arises whether or not the human mind is an
element of the process. [ Reply to This | # ]
|
| |
| Authored by: jimrandomh on Monday, March 11 2013 @ 12:56 AM EDT |
| The primary problem with software patents is that in practice they have
been
used primarily as a vehicle for racketeering and barratry. To
software
practitioners, the patent system is no longer a business
regulation but a
personal threat of being extorted. The public sentiment
towards software
patents, among actual independent inventors, is
fear and anger, and it
appears to be justified. That - not any
legal issue or cost-benefit analysis -
is the real heart of the issue. [ Reply to This | # ]
|
| |
| Authored by: swmcd on Monday, March 11 2013 @ 01:05 AM EDT |
| When computing, the computer writes symbols
that have the same semantical relationships. [ Reply to This | # ]
|
| |
| Authored by: swmcd on Monday, March 11 2013 @ 01:07 AM EDT |
Computers use electrical, magnetic and optical
phenomenonsa to represent
bits.
OR
Computers use electrical, magnetic and optical
phenomenonsmedia to represent bits. [ Reply to This | # ]
|
| |
| Authored by: swmcd on Monday, March 11 2013 @ 01:09 AM EDT |
Finally, the numbers means whatever in the
universe[ Reply to This | # ]
|
| |
| Authored by: swmcd on Monday, March 11 2013 @ 01:12 AM EDT |
| This is part of the mathematical foundations of computer
science. [ Reply to This | # ]
|
| |
| Authored by: swmcd on Monday, March 11 2013 @ 01:20 AM EDT |
Most modern general purpose computers are
buildt according to the stored program
computer architecture.[ Reply to This | # ]
|
- typo - Authored by: OpenSourceFTW on Monday, March 11 2013 @ 01:33 AM EDT
- Request - Authored by: Anonymous on Monday, March 11 2013 @ 09:51 AM EDT
| |
| Authored by: Anonymous on Monday, March 11 2013 @ 02:06 AM EDT |
Compare a computer to an abacus. The beads are the bits of data. Moving the
beads does not create a new machine.[ Reply to This | # ]
|
| |
| Authored by: Wol on Monday, March 11 2013 @ 06:14 AM EDT |
Actually, when I started programming in the 80s, I understood that there was
quite strong feeling that they should be.
Some compilers - FORTRAN in particular - would assume that given the same input,
they would always get back the same output. And they didn't like it if that rule
got broken!
In that sense, a software function IS a mathematical function - the calling
program cares nothing about the function internals, the compiler merely cares
that the output is consistent from one use to the next.
Cheers,
Wol[ Reply to This | # ]
|
| |
| Authored by: Anonymous on Monday, March 11 2013 @ 06:43 AM EDT |
One problem with software patents is the issue of Trade Dress. The old
look and feel issue. If slide to unlock is a Trade Dress patent, then a
whole class of actions are blocked, even if software patents are
eliminated.
The length of software patents is too long. Putting look and feel under
patent protection, instead of copyright protection does have the
advantage of much less than life of the author plus 75 years. But with
the speed of computer development even patent protection is too long.[ Reply to This | # ]
|
| |
| Authored by: rebentisch on Monday, March 11 2013 @ 09:43 AM EDT |
I am sorry to tell but the "software is math" argument against patenting does
not sell. It is lucid evidence for mathematicians and computer scientists but
not taken seriously in the legal community.
"Software consists of
algorithms, in other words mathematics, and data, which is being manipulated by
the algorithms. Mathematics is not patentable subject matter and neither is
data. On what basis, then, is software patentable subject matter?"
The question fails to address why mathematics isn't patentable.
In principle (the specific legal situation aside) everything is patentable that
someone wants to be patentable and could describe with a abstract "technical"
description, the "invention". The lucid proof to say software is math, math is
unpatentable, thus software unpatentable completely misses the point. If
software/math is not patentable it is because a decision is made that the scope
of inventions does not extend to software/math.[ Reply to This | # ]
|
| |
| Authored by: swmcd on Monday, March 11 2013 @ 11:00 AM EDT |
I'm really concerned about this paragraph
There is room to argue
whether a number is an interpretant, a thought in the mind of humans, or an
abstract referent, something that exists in a parallel abstract universe. This
is a controversial topic in the philosophy of mathematics. A similar question
may be raised with such concepts as commodity hedging. The law shouldn't be
concerned with this debate. Either way the mathematical entities are abstract
and not patentable. It should be acceptable to assimilate abstract referents
with interpretants for legal purposes.
It brings in a level of
meta-analysis that is probably unnecessary, likely to confuse, and will give the
courts more word-fodder for their misguided and incorrect opinions.
The
courts are running around saying that algorithms aren't abstract if they can be
implemented on a physical computer and programming a computer makes it a
different machine. They don't have the basic concepts that they need to deal
with software patents. We are trying to give them a semiotic framework that
distinguishes between sign-vehicle, interpretant, and referent. And then we
say
It should be acceptable to assimilate abstract referents with
interpretants for legal purposes.
They are going to read this as
word-salad and go on their merry way patenting algorithms, because, you know,
it's all just math stuff anyway.
If this paragraph stands, then at the very
least we need to
- define abstract referent
- write
assimilate ... into in place of assimilate ... with and be
very clear about what is being assimilated into what.
[ Reply to This | # ]
|
| |
| Authored by: ukjaybrat on Monday, March 11 2013 @ 11:17 AM EDT |
I'm not sure where this would fit in to any of these four
topics or if anyone even shares these feelings.
If after all of this settles we are still awarding what we
consider bogus software patents, the 20 year monopoly is
extremely too long. When patent concepts first came up, i'm
sure that someone did an analysis and determined 20 years
was about right. But software is always moving, changing,
innovating. Something you bought last month is already
deprecated due to the next newest thing. a 20 year monopoly
on a technology that, unencumbered by a patent, could be re-
innovated upon in much less time. But because there is legal
20 year monopoly, the holder of said patent has no
obligation to do anything with that technology.
I'm sure a lot of what i just said was duplicate material
covered in the section about "software patents hinder
innovation" ... but my point is that if we are stuck with
software patents, the duration should be much much less than
20 years... 5 years even seems a bit much but at least more
reasonable than 20 years.
thoughts?
---
IANAL[ Reply to This | # ]
|
| |
| Authored by: Anonymous on Monday, March 11 2013 @ 11:31 AM EDT |
Here's Groklaw's proposed response to the USPTO's request
for
suggested topics for discussion in the future by the
Software Partnership,
as it calls it.
Please try to provide the topics and not
the
rhetoric! As a reader, I very much dislike having to read a
response to a
question when the only thing asked was the
question. I know it is hard but
USPTO appears to want topics
and may of these digress into rhetoric of what is
wrong.
Also please note that the USPTO only cares about the USPTO
so things
should be framed in terms of helping the USPTO.
Missing in Topic 3 are
the aspects of clearly defining
patents. I thought that may people commented on
the fact
that software patents should be more expressive of the
software
implementation. Many software patents appears to be
written in terms of a
physical machine but the reality is
virtual. It would be much easier for the
USPTO if software
patents had a specific set of requirements especially to
find and understand prior art. For example, determining that
a patent claim is
just a numerical method to solve an
equation.
In Topic 4 you are missing
the aspects from the Mayo
ruling where there was the view that a combination of
unpatentable ideas may in fact be patentable. If such a
combination is
patented then do you have to have just that
specific combination to infringe?
Also, can software patents
be valid as part of some new physical machine like a
self-
ware robot?
Topic 4 is incorrectly focused on the mathematics when
really software patents are about an algorithm (as in
a specific set of
predefined steps). This totally avoids any
misunderstandings of what is and is
not mathematics or laws
of nature. Really software is a recipe (that can be
patented) patent on software need to have similar rules to
recipe patents.
[ Reply to This | # ]
|
| |
| Authored by: Anonymous on Monday, March 11 2013 @ 12:08 PM EDT |
Fair warning, I am in no ways a legal writer/expert/anything so these are all
from a layman's perspective
Section A (part?) 2 at the bottom of "A
function is not an algorithm"
Despite the similarly sounding
words, a software function is not the same thing as a mathematical function.
However the two concepts are closely related. If we look at the underlying
principles of mathematics which are at the foundations of computer science the
functions of software are described with mathematical functions. The methods
used to perform the functions of software are implemented using mathematical
algorithms.
It really just leaves me confused about what you are
trying to say. A function isn't a software function, a software function is
described by a function, the 'methods used to perform the functions of software'
(whatever that means) are 'implemented' (but aren't actually?) using
mathematical algorithms.
Section A (part?) 4 paragraph 3:
For the sake of comparison, here is an example of a procedure which is not an
algorithm: Interim Examination Instructions For Evaluating Subject Matter
Eligibility Under 35 U.S.C. § 101 (PDF). Legal procedures such as this one
require the human to consider the meaning of the information and then inject
additional information based on his experience, knowledge, and convictions to
reach a decision. They require a lot of insight and ingenuity to be executed and
for this reason they are not mathematical algorithms.
Nitpicky,
but using the words "They require a lot of insight" seems to imply that
minimal amounts of insight might be ok... which they aren't...
Section
B (part?) 3 paragraph 3:
What kind of non mathematical meanings
must be given to the numbers to make a patent eligible difference in the
calculator circuit? Answer: it can't happen
The answer doesn't
feel right for the question, it says "it can't happen" but what is trying to
happen in the first place? Reword somehow?
Section C (part?)
1
This whole part feels wrong to me. Addition is no less abstract if it
only works on numbers between 1 and 10, nor are computers made to handle
infinite data sets (limits on available memory). In fact if a requirement to be
"Abstract" is to handle a "potentially infinite range of inputs" then no
computer program (though probably quite a few patents these could be easily we
worded) are abstract ideas, for they all use concepts such as "ints" and
"floats" that have limited ranges to represent numbers.
section D
(part?) 1 repeats stuff about the number of patent lawyers needed to keep up
with new software patents from a previous section, I'm not sure if this is
considered bad.
Also in D 1 you have one calculation using 10 minutes
to examine a patent and one using 1 hour, again I'm not sure if this is
considered a bad thing.[ Reply to This | # ]
|
| |
| Authored by: Anonymous on Monday, March 11 2013 @ 12:32 PM EDT |
I tend to think in terms of simpler language -- if I hear "referent"
and "interpretant" my brain begins to melt. On the other hand, I have
a background in computer languages, so I tend to think in terms of that
language, so... I might be biased. :P
Anyways, here's an alternative version of the argument with my field's language
used. We can think of anything that can be drawn or written as a
"symbol" (the "sign-entity" of semiotic theory). I'll be
using the term "sign" to mean "sign-entity" here, although
they are distinct. In parsing, we'd call those "tokens". In
cartography they'd be called "maps". I intentionally chose cartography
as my secondary domain of discourse because it also can be a graphical
explanation of the ideas. The same can be said of "equations" and
"graphs" in algebra and calculus. I'll use parsing as my primary
domain though.
In parsing, we divide up an input text into "tokens". These can be
placed into a "structure" of tokens -- a sequence, like a list, or a
graph structure. Any of these can be drawn, so they are symbols. A control-flow
graph (which traces function calls in a program) is also a symbol, because it
can also be represented as text or it can be drawn, as can a data-flow graph or
the non-directed graphs used to represent functional programs (for lazy
functional languages which use substitution and graph reduction as their
calculation method). In fact, any representation of software falls into this
category. (The same can be said of any representation of data that can be
expressed on a computer.)
An interpretant in semiotics is probably better called an
"interpretation" or "inference" in normal, everyday speech,
although those terms have another meaning in computer science and language
theory. Really, the interpretation can be thought of as how a human gets meaning
from data -- the ideas inferred from what we're reading. A map is a symbol (it
can be drawn), and the interpretation of the map is the idea you get in your
head of the shape of the land based on the symbol. But there's an old saying --
the map is not the territory, just as your interpretation of the map is not the
land itself (which is the referent). In software, the interpretation of the
program is the input, the output and the actual steps performed when you're
trying to figure out how it does what it does. You may well write out sample
data on paper and perform the same steps the computer would, also on paper, to
figure out where the bugs in a program are. The paper-based writing is still
just symbols, and your thoughts are the meaning. The symbols themselves don't
have meaning without someone giving it to them.
As for the referent, I tend to think of that as the real-world object being
described, but "object" also has a different meaning in the computer
field. Maybe "physical object" or "subject" would be better.
In cartography, you can think of this as the actual land. You can't build a
house on a map, nor on the idea you have in your head as to the shape of the
land by reading one. It's the subject of the map, the land itself, that's real,
that's usable for construction. Most software doesn't have such a physical
correspondence with the real world. Considering programming a computer to make a
new machine is the same as considering dialing a specific phone number to create
a new phone system -- they both make changes in the state of the wiring in the
system, which results in the circuit pathways being changed. It's possible to
have an automated system set up so that when you dial certain numbers you
perform different mathematical operations (when you dial one number, you get an
automated adder that asks you to input two numbers on the phone, adds them, and
reads the result back). A list of phone numbers with a list of numbers to enter
in when you reach them is probably not patentable, but is analogous to machine
instructions and their arguments (assuming you never have to redial due to a
busy signal -- or maybe that condition's not even needed, since that can be
thought of similarly to data bus contention and wait states).
To go to algebra and calculus, the equation y=+/-square_root(1-x^2) is a symbol.
You think of the graph of that equation in your head, in which case it can be
the interpretation of the equation. In this case, the physical object is also a
symbol, that is, a circle of radius one. As a result, it's really an abstraction
on multiple levels.
The first thing a computer scientist is taught is that all software is
abstraction -- we substitute symbols for real things, for ideas, and for other
symbols. We try to simplify problems by breaking them down into smaller and
smaller pieces, each of which is symbolic of a subset of the larger problem.
Even the term functional decomposition, which is the main task of computer
science, is indicative of abstractions and simplifications, and the mathematical
consequences thereof.
I do have to say that the contributor who suggested semiotics as the basis for a
test was pretty sharp. I can't imagine a better starting point.
(By the way, in terms of patents, one can also note that they are, themselves,
symbols -- the words on paper represent the idea of how to make the product, but
only the product itself is covered by the patent. You can make as many copies of
the patent paperwork itself as you want, and you can read it and understand it
if you want, without infringing. Theoretically, unless certain companies get
their way. :P )[ Reply to This | # ]
|
| |
| Authored by: Guil Rarey on Monday, March 11 2013 @ 12:51 PM EDT |
In particular the discussion of semiotics struck the wrong note for me. The
explanation was too much "trying to explain graduate level topics to high
school students.". Either the audience can handle an adult level discussion
of semiotics or they can't. if they can it should perhaps be revisited for
tone. if they can't, perhaps the whole thing needs to be shifted to the
supporting materials.
---
If the only way you can value something is with money, you have no idea what
it's worth. If you try to make money by making money, you won't. You might con
so[ Reply to This | # ]
|
| |
| Authored by: Anonymous on Monday, March 11 2013 @ 01:26 PM EDT |
In fact a particular aspect of that analogy springs to mind in which the
computer is clearly more abstract than the printing press.
As a hobby, I do
letterpress printing. Consider the delightful piece of engineering that is the
Heidelberg Windmill press - many of which, like the one shown on this youtube video, are
still running despite being manufactured in the 50's and 60's. (My own press is
significantly less of an engineering marvel)
As delivered from the factory,
this one and a half tons of (mostly) iron and steel could not print a single
word, could neither die-cut paper and card nor score it for folding. It could
not hot-stamp foil designs onto paper. (these latter functions other than
transferring ink to paper are the main reason many commercial print shops still
keep a platen letterpress around)
To go to the cabinet, take a case with its
font of type over to the workbench and compose a form, lock it into the chase
and fit that chase into the press has definitely added hardware in the form of a
couple pounds of metal, but it hasn't made a new machine. The machine operates
as it always had, but now every cycle, every turn of that monster flywheel,
results in whatever symbols I composed being transferred from my imagination to
a page.
The computer and its software are even more abstract than that - the
symbols it manipulates have no "real" instantiation until ephemerally displayed
or transferred to a more permanent medium.In fact there is a clear progression
visible in the handling of information from well before the printing press to
todays computers, with the accompanying increase in the abstraction of that
information from the means by which it is handled.
Prior to Gutenberg,
symbols denoting information were inscribed by hand as complete words, their
informational content recited mentally by the scribe even as his hands directed
his pen to transfer the symbols to the page. Gutenberg provided the first
abstraction here, with mechanically reproduced movable type where the physical
reality of the symbols was reduced to the individual letters, those individual
pieces of type being stored between jobs and reassembled into more complex
symbols carrying different information at each re-use. Essentially the exact
same process I perform every time I set type for my more modern press.
The
next stage in abstraction is of course the hot metal methods of printing, where
even the individual letters do not survive in physical form between jobs. In
machines such as the linotype you bash on a keyboard to arrange molds of your
letters and the machine casts them as required - and they then get locked up
into a press and printed from, only to be melted down again when the job is
done. The printing press still works exactly the same way, it makes no
difference whether the form of type being inked and printed is composed of
individual re-usable letters or whether it is an ephemeral block of cast lines
destined to lose its form again in the melt-pot.
The computer provides the
final abstraction - there is no physical reality to the symbols carrying the
information until the moment of impression where a computer printer places ink
directly on the paper. In a very real sense, particularly when one considers
phenomena such as just-in-time publishing, the computer has abstracted not only
the physical representation of the symbols but also the press itself from the
process.
The information, the meaning, the actual true nature of the symbols
themselves and the process by which that meaning is manipulated, however,
remains unchanged. [ Reply to This | # ]
|
| |
| Authored by: Tkilgore on Monday, March 11 2013 @ 01:44 PM EDT |
Several people have obviously worked very hard on this document, so I hope that
nobody takes this the wrong way. But the following is difficult not to notice:
A disproportionate number of the comments are devoted to nothing else but to
point out typos and errors in grammar, spelling, or style. These comments are
already of such a number that I do not see how anybody could assimilate them all
and correct them all, one by one. I have read through the document and I have
found quite a few places where such corrections are needed, myself. But I found
so many small corrections that are needed, that I have no idea whether or not
the many comments calling for corrections have covered everything I found
myself, or not. The situation shows a danger of becoming chaotic, and I
understand that there is a deadline to meet.
Thus, quite aside from any discussions about content, it strikes me that what is
most urgently needed is a good proofreading and resulting cleanup of the
document. Then perhaps we can start over again about looking for typos and small
corrections, not to mention continuing the more substantive discussions?
From past experience, I am well aware that I am not the world's best
proofreader. But having pointed out in public the need to do this, I am of
course willing to take on some of the work.[ Reply to This | # ]
|
| |
| Authored by: swmcd on Monday, March 11 2013 @ 04:06 PM EDT |
I'm not sure the contrast between ENIAC and modern computers advances our
case.
Some old general purpose computers like the ancient ENIAC
were programmed by physically rewiring the computer using a plug board. This
kind of programming makes a particular circuit for each program. This is an
obsolete design. Most modern general purpose computers are build according to
the stored program computer architecture. They are not programmed with plug
boards or equivalent devices. These computers are programmed through a
combination of two techniques: (a) defining the meaning of data, and, (b) giving
some input to an already implemented algorithm. These two techniques, taken
alone or in combination, do not configure the computer to make a specific
machine. They leave the structure of the machine unchanged.
(a)
The programmers who programmed ENIAC with cables and plug boards also had to
define the meaning of data.
(b) Does "input" here refer to the data that is
provided to the program, or does it refer to the program itself, which is
regarded as input the instruction cycle that is implemented by the
CPU?
Rather than allowing that their "new machine" doctrine applies only to
obsolete hardware, lawyers and judges may consider that replugging an ENIAC and
flipping bits in RAM are exactly the same sort of operations:
they both reconfigure the hardware to create a new machine. [ Reply to This | # ]
|
| |
| Authored by: swmcd on Monday, March 11 2013 @ 04:14 PM EDT |
I think the printed matter doctrine is one of our stronger arguments. Any chance
we could cite player pianos as another kind of machine that falls under under
this doctrine?
If the courts are going to insist that every computer program creates a new,
patentable machine, then I want a patent on my player piano with the Mozart
sonata #1 roll installed, and a patent on my player piano with the Mozart sonata
#2 roll installed, and a patent on my player piano with the ...[ Reply to This | # ]
|
| |
| Authored by: albert on Monday, March 11 2013 @ 05:02 PM EDT |
The abstract is excellent.
Bearing in mind the non-technical audience it's
written for:
Topic 1; good
Topic 2; too much text on the impossibility of s/w patent searches (for want of
a better term). Cite it, then cite a study or two showing the actual economic
effects of s/w patent lawsuits, both in legal cost terms, and, more importantly,
the freezing effect of lawsuits on product development.
Topic 3; I still like the printing press analogy.
Topic 4; Don't introduce alien terminology. Leave semiotics out entirely. Use an
analogy like a simple pictographic (no text) road sign. Everyone can understand
the difference between the 'sign holder' (plate and pole), the 'symbol' affixed
thereto (pictograph), and the 'meaning' of the symbol.
Overall, an excellent effort. Kudos, and thanks to PJ and all the groklawers
(groklawians?) who contributed to this project.
[ Reply to This | # ]
|
| |
| Authored by: IMANAL_TOO on Monday, March 11 2013 @ 07:03 PM EDT |
Now the structure layout of the Supplement solely relies on formatting, not the
subtitle ordering.
The Letter A's (of Factual background) centered alignment is the only thing that
tells you it is superordinate to the following "1." (of Semiotics).
If you watch the document on a small screen (Android, iPad etc) you immediately
get lost as there are several unnumbered subtitles beginning with
"1."
1. Semiotics defines the concepts
1. The proper understanding
1. Mathematical algorithms
1. Clearing all patents rights
Of course there are several which begin with 2., 3., etc.
While redundant on a large computer monitor it would be most useful (at least to
me) have them numbered, perhaps like:
A.1. Semiotics defines the concepts
B.1. The proper understanding
C.1. Mathematical algorithms
D.1. Clearing all patents rights
Yes, expanding it one level as A.1.1 may be too clumsy, but would also be useful
for some of us.
That way you don't lose track of your reading, if you like me have to stop
reading your smartphone every five minutes or so beccause you get interrupted.
The supplement still needs bulleting, for those who read it on a smartphone or
don't necessarily have a quiet office.
---
______
IMANAL
.[ Reply to This | # ]
|
| |
| Authored by: pdundas on Tuesday, March 12 2013 @ 08:46 AM EDT |
Some additional questions, not in the list. Feel free to add
more here...
5. What are costs to the economy of software patents? What
is the aggregate dollar value of all these
costs?
6. What are the benefits to the economy of software patents?
Does the value outweigh the costs above?
7. Can innovation in computing be adequately (or more
efficiently) protected by copyright law, rather than
patent law?
8. Is the current term of patent protection appropriate for
software patents? Should it be shorter? If so,
how short?
9. Should software patents require working code, or well
defined pseudo-code, to enable practitioners
normally skilled in the art (even patent attorneys) to
understand what is being described?
10. Exactly what additional technical or other requirement
is necessary above and beyond an algorithm
running on a general-purpose computer, for an invention to
be patentable?[ Reply to This | # ]
|
| |
| Authored by: Anonymous on Tuesday, March 12 2013 @ 04:55 PM EDT |
Software exists in a set of one or more text files. Sometimes a text file is
treated as data. Other times the text file is executed. There is no universal or
clear basis for making the distinction between data and executable text. If the
US patents text files, the US patents data, writings, information, APIs, ABIs,
mathematics, physics, science. These are written artifacts of human thought, not
patentable systems or processes.
Since any software patent "subsumes all hardware as commodity", any
such US patent is a legal monopoly over all possible computer solutions with
similar inputs and outputs. Text files are the only evidence to support a
software patent.
While patenting hardware has proven economic value, patenting all solutions with
similar inputs/outputs is obviously bad for business. So, business will continue
to leave the US along with all the US profits. Any five year old knows the
difference. Patent the hardware. Copyright the software. One cannot patent
mathematics or data. One cannot patent all solutions to a problem. Any kid knows
that is bad for business.
There is more... Few US software patents actually contain anything close to an
approximation of a practical solution to a problem, just inputs/outputs. An
expert in the field would not gain any knowledge from the granted patents. The
US is patenting all computerized systems with similar inputs/outputs. This is
tantamount to patenting mathematical function signatures (i.e., inputs,
outputs). The US is patenting APIs sans implementations.
The US patent system is functioning at the primitive level of a "cargo
cult" with respect to computers. In the movie "The Gods Must Be
Crazy" it was an aborigine finding an empty coke bottle (not even knowing
it had been full of soda, drunk, and tossed out). In US patent courts, US judges
are commenting out loud that a text file is large and complex, these judges not
even knowing it is been full of 1+1=2, etc. Epically clueless.
Many US software patents exist even though US legal experts claim they do not.
Patent thickets are an existential risk to US industries. US patent courts are
inventing US law from whole cloth, but the SCOTUS could stop them. The US
legislature is failing to deal with patent law. Intellectual property across the
globe is at risk. More flawed, draconian laws will only hasten the systemic
collapse. After S&L, dot com, and residential real estate failures, an IP
failure is lined up to go next.
It has been estimated there are 1,500 to 2,500 existing patents applicable to
any smart phone. Patent trolls think the number is much higher.[ Reply to This | # ]
|
| |
| Authored by: Anonymous on Wednesday, March 13 2013 @ 04:48 PM EDT |
pj and everyone at Groklaw, thanks a lot for the work you've been putting into
this! I sincerely hope it will help to make my daily legal again - I write
hundreds of lines of code every day and I simply have no idea how many patents
and laws a break by doing that.
This is insane.[ Reply to This | # ]
|
| |
| Authored by: Anonymous on Wednesday, March 13 2013 @ 04:51 PM EDT |
I'm not feeling well, so please bear with me if this has been mentioned before
but I just can't read all the text and the comments right now :-(
There is a simple way to turn any computer program into a number:
- Read the code into a byte array
- result = 0
- for each byte: result = result * 256 + byte
The result you get is a numeric representation of the program. It's a huge
number, sure, but how can a number ever be patentable?[ Reply to This | # ]
|
|
|
|
|