|
|
| How The Kernel Development Process Works, by Greg Kroah-Hartman |
 |
|
Sunday, May 29 2005 @ 02:54 PM EDT
|
I asked Greg Kroah-Hartman if he'd write an article explaining the Linux kernel development process. One of the most common FUD themes is to imply that unknown, untrusted parties are contributing heaven-knows-what to the Linux kernel. This is totally inaccurate, in fact it's upside down from the truth. The truth is every little piece is chronicled from the moment it is submitted. That isn't the only misconception about the Linux kernel development process.
As you know, The SCO Group, in its discovery requests in SCO v. IBM, asked for all non-public IBM contributions to Linux. Linux is developed in public, so when I read their request for nonpublic patches, I realized there is a need to explain the process. Greg is the current Linux kernel maintainer for, as he puts it,
"more driver subsystems than he wants to admit, along with the
driver core, sysfs, kobject, kref, and debugfs code." He
currently works for Novell's SuSE Labs, doing Linux kernel
development-related things. He is also one of the authors of the best-selling book, "Linux Device Drivers." I also asked Andrew Morton what would happen if someone did try to submit a patch privately, because Greg wrote that occasionally that happens if a company or an individual is new to Linux and doesn't realize that Linux is developed in public, that there is a public review process, and a right way to offer submissions. If that happens, then what? Here is Andrew's answer, which matches what Greg writes: Occasionally people will send me a patch off-list. If the patch is trivial
I'll sometimes merge it into my tree and will later send it on to Linus.
But on most of those few occasions when I get an off-list patch I'll ask
the submitter to resend it with a Cc to the appropriate mailing list so
that it gets appropriate review.
But even if a patch is sent off-list to a subsystem maintainer, it is still
open to review in the -mm tree prior to being merged into Linus's tree.
And, ultimately, *all* patches which go into Linus's tree are
simultaneously sent to the `commits' mailing list for all interested
parties to review. All patches on the commits list have the full
attribution trail so we can see who was involved. Because of the commits
list it is simply not possible for anyone to slip a patch into the kernel
without a heck of a lot of developers knowing about it.
IBM, of course, knows the procedure for submitting patches to Linux. So while others who are newer to Linux might get confused and attempt to send directly to a maintainer, IBM is not likely to have ever done so. Even if they had tried, it would have been made public by the individual who received the email or someone further up the chain. The key point of Linux development is that there is a public review process, a review by many eyeballs. The qualilty is built into that development process. Bypassing that public review vitiates that power, so it is avoided. Note that Greg lists two references for those who wish to know how to properly submit a patch. Here's a third, a talk Greg gave in 2002 on proper Linux kernel coding style, one of the many interesting things on his Greg K-H's Linux Stuff web site.
***************************
How the Linux Kernel Development Process Works
~ by Greg Kroah-Hartman
There seems to be a lot of misunderstanding about how code actually
gets into the Linux kernel. People are claiming that code can just get
"slipped into" the main kernel tree without realizing where it really
came from, or without any sort of review process. Obviously they have
never actually tried to get a major kernel patch accepted, otherwise
they would not be making these kinds of claims :)
First, what do we mean when we speak of a "patch"? In order to get any
kind of change accepted into the kernel, a developer has to generate
something called a "patch" and send it to the maintainer of the code
they are changing (more on that process below.) To do this, they make
the changes needed to the specific part of the kernel that they wish to
modify, and then run a tool called 'diff'. This tool generates a human
readable file that shows exactly what lines of code were modified, and
what they were changed into. A very simple example of this can be seen
here:
--- a/drivers/usb/image/microtek.c
+++ b/drivers/usb/image/microtek.c
@@ -335,7 +335,7 @@ static int mts_scsi_abort (Scsi_Cmnd *sr
mts_urb_abort(desc);
- return FAILURE;
+ return FAILED;
}
static int mts_scsi_host_reset (Scsi_Cmnd *srb)
This shows that the file, drivers/usb/image/microtek.c had one line of
code changed. From:
return FAILURE;
to:
return FAILED;
This bit of text can then be emailed to other people, who can instantly
see that yes, it only changes 1 line of code, and yes, this is probably
a correct thing. Then they run another program called 'patch' and give
it this bit of text. The patch program then modifies the specified file
in the specified way. Because the developer uses the program 'patch' to
apply this bit of text, the bits of text themselves have come to be
called 'patches'.
All Linux kernel development is done by sending patches though publicly posted email.
If you take a look at the main Linux kernel development mailing list,
you will see hundreds of these patches being sent around, discussed,
critiqued, and even accepted, into the main kernel tree. This is how
kernel development is done.
If you wish to know more about how to create a patch that is acceptable
to the kernel developers, please see the file,
Documentation/SubmittingPatches for more information as to
what is needed to be specified in the patch, and how to compose it. Also,
other good references are these files:
Andrew Morton's description of the "perfect patch":
http://www.zip.com.au/~akpm/linux/patches/stuff/tpp.txt
Jeff Garzik's description of what to include in a patch to make it easy
for others to understand it:
http://linux.yyz.us/patch-format.html
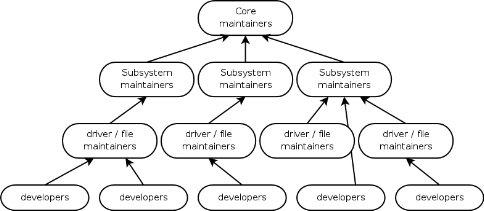
Now, who is generating these patches, and who does anything with them?
The Linux kernel development group is a vast group of people that have
structured themselves in a pseudo-pyramid form. At the base of the
pyramid are the hundreds of developers who write anywhere from 1 to 2000
different patches. At last count, there were about 1,000 different
individual contributors to the 2.6 Linux kernel. These developers send
their patches on to the maintainer of the file or groups of files that
they have modified. These maintainers are spelled out in the file
MAINTAINERS that is in the main Linux kernel source tree. There are
about 300 different maintainers currently. If the maintainer feels that
the change is a proper one, and they agree with it, they then send these
changes off to the subsystem maintainer for the major part of the kernel
being modified. Subsystem maintainers are present for almost all parts
of the kernel, examples of which are, networking, USB drivers, Virtual
File System, module core, driver core, Firewire drivers, network
drivers, and so on. These people are also listed in the MAINTAINERS
file, and all individual file and driver maintainers know who these
people are to send these changes to. Then, the subsystem maintainers,
if they agree with the change, then submits the patches to Linus
Torvalds or Andrew Morton, depending on what they are used to doing, and
from there it makes it into the main kernel source tree. Note, that
every person who touches the patch along this chain of submission, adds
a "Signed-off-by:" line to their code, which shows exactly where the
change came from, and who approved it. A number of us kernel developers
call this the "trail of blame", meaning that if someone has a problem with the
change, we know exactly who to blame for the issue.
I originally stated that this is a "pseudo-pyramid" structure. I said
this as the full process of sending patches do not always flow in such a
neat way. Sometimes people short-circut the maintainer of a subsystem,
and send a patch directly to Andrew or a mailing list. Other times, a
subsystem maintainer will modify code that is controlled by another
maintainer, and not specifically get their blessing before submitting it
on upward. Also, maintainers and subsystem maintainers are always
changing, as new people come into kernel development, and older ones
leave.
Sometimes a patch is submitted directly to a maintainer,
without being sent to a public mailing list. This usually happens by new developers who are not
used to the whole review process, and occasionally happens for "trivial"
patches, that simply fix an obvious bug. For small 1-2 line
bugfixes, the maintainer might accept them directly, and then
accumulate them in their development trees (which are all
publicly available in Andrew Morton's -mm kernel releases.) But
for bigger patches, the maintainer usually asks the submitter to
resend them and CC: a public mailing list in order for other
developers to review them. If that never happens,
the patch goes nowhere.
How do the patches go from person to person?
All development is done through email. Developers send patches through
email to other developers by sending them to different mailing lists.
There is one main mailing list for all kernel development,
linux-kernel. This list gets about 200-300 emails a day, and
almost all aspects of the kernel are discussed on it. Because of the
high volume on it, almost all different subsections of the kernel have
formed their own mailing lists, in order to get work done and focus on a
specific area. Some examples of specific mailing lists are:
All of these mailing lists are archived by a wide range of different
archive sites, allowing people to go back in time and see what happened,
and search for specific things. Some examples of archive sites are
http://marc.theaimsgroup.com/
and
http://www.gmane.org.
So a patch is posted on a mailing list. Other developers then critique
the patch, and offer suggestions, again, copying the mailing list for
everyone to see. Eventually some kind of consensus is reached, and the
patch is accepted by the maintainer to submit on up the chain. All of
this is done in public, for everyone to see, and archived, in public,
again, for everyone to see.
As an example, recently someone submitted a small patch that added a new
function and changed a few others in order to support a new type of
hardware the is being created. That can be seen here:
http://thread.gmane.org/gmane.linux.kernel/297422
A number of different developers chimed in, and offered suggestions as
to how to make the patch better:
http://article.gmane.org/gmane.linux.kernel/297427
and:
http://article.gmane.org/gmane.linux.kernel/297463
The original author took those comments, and then created a new patch:
http://article.gmane.org/gmane.linux.kernel/297675
which was then commented on, and the development continued.
This is how kernel development usually works, in the open, with everyone
being able to see everything that happens. That is why when people
complain about not knowing everything that a specific company has done
for Linux, they are usually very misguided.
|
|
|
|
| Authored by: Anonymous on Sunday, May 29 2005 @ 03:06 PM EDT |
| How can we speedup the legal process? [ Reply to This | # ]
|
- OT Here-- Can the legal process be improved 2nd here. - Authored by: Anonymous on Sunday, May 29 2005 @ 03:42 PM EDT
- EU constitution news - Authored by: Anonymous on Sunday, May 29 2005 @ 04:24 PM EDT
- Anonymous Posts - Authored by: MeinZy on Sunday, May 29 2005 @ 04:35 PM EDT
- Anonymous Posts - Authored by: MathFox on Sunday, May 29 2005 @ 04:40 PM EDT
- Anonymous Posts - Authored by: Anonymous on Sunday, May 29 2005 @ 05:31 PM EDT
- Anonymous Posts - Authored by: jailbait on Sunday, May 29 2005 @ 05:33 PM EDT
- Anonymous Posts - Authored by: Anonymous on Sunday, May 29 2005 @ 05:55 PM EDT
- Anonymous Posts - Authored by: Anonymous on Sunday, May 29 2005 @ 06:12 PM EDT
- Anonymous Posts - Authored by: Tufty on Sunday, May 29 2005 @ 06:48 PM EDT
- Anonymous Posts - Authored by: Avada Kedavra on Sunday, May 29 2005 @ 08:56 PM EDT
- Anonymous Posts - Authored by: grundy on Sunday, May 29 2005 @ 10:17 PM EDT
- Being a man... - Authored by: Anonymous on Sunday, May 29 2005 @ 11:51 PM EDT
- Anonymous Posts - Authored by: Anonymous on Monday, May 30 2005 @ 09:41 AM EDT
- One simple reason..... - Authored by: tiger99 on Monday, May 30 2005 @ 10:50 AM EDT
- Windows and Unix Tied in New Server Sales - Authored by: Anonymous on Sunday, May 29 2005 @ 04:43 PM EDT
- Lawrence Lessig's other court case - Authored by: Anonymous on Monday, May 30 2005 @ 06:49 AM EDT
- Humour, Microsoft changes core folder names. - Authored by: Franki on Monday, May 30 2005 @ 09:39 AM EDT
- Hunting season fo MSFT? (Enderle Article) - Authored by: Anonymous on Monday, May 30 2005 @ 11:22 AM EDT
- Linux Device Drivers, Third Edition - Authored by: nadams on Monday, May 30 2005 @ 11:31 AM EDT
| |
| Authored by: meshuggeneh on Sunday, May 29 2005 @ 03:17 PM EDT |
I only wish I'd read Greg's pages before getting this cheesy Belkin
"PDA" usb-RS232 adapter: Then I'd have known it is NOT compliant with
RS232.
[ Reply to This | # ]
|
| |
| Authored by: Anonymous on Sunday, May 29 2005 @ 03:39 PM EDT |
In particular, in large proprietary companies, are there third-party auditors
that check every checkin for security and any obvious IP violations?
It seems these practices Greg KH described are very important for creating
software relatively free of bugs, espeically security bugs. It'd be nice to
see if government purchcasing mandated that third parties audited every checkin
of any software they buy. Perhaps the large auditing companies (Accenture, etc)
could provide such a software for the big proprietary companies if they're not
doing this already.[ Reply to This | # ]
|
| |
| Authored by: Chris Lingard on Sunday, May 29 2005 @ 03:45 PM EDT |
I think the article gives the idea that patches are accepted easily. The
level of knowledge to post a sensible patch is high. Most patches come from
known and trusted developers.
To learn enough to join that team, is a
steep learning curve.
I have posted patches that are perfectly
sensible; but have been rejected because of the "many eyes" that review
everything, spot that it would break something else. And that is the true
advantage of open source, and why it is superior.
[ Reply to This | # ]
|
| |
| Authored by: brian on Sunday, May 29 2005 @ 03:47 PM EDT |
"The SCO Group, in its discovery requests in SCO v. IBM,
asked for all non-public IBM contributions to Linux. Linux
is developed in public, so when I read their request for
nonpublic patches, I realized there is a need to explain
the process."
I can see a way that a patch wouldn't be public. It doesn't
help SCO any but it is possible...
As everyone knows, the GPL doesn't require release of code
that is not distributed. It is possible SCO is referring to
the "in-house" patches that never got released. Remember,
if IBM put code into Linux (even in-house) it was doing so
in violation of their "revoked" license to do so.
Hey, it isn't my theory so don't gang up on me!
B.
---
#ifndef IANAL
#define IANAL
#endif[ Reply to This | # ]
|
- SCO's Non-Public Patches - Authored by: Anonymous on Sunday, May 29 2005 @ 03:55 PM EDT
- SCO's Non-Public Patches - Authored by: Anonymous on Sunday, May 29 2005 @ 04:00 PM EDT
- SCO's request for Non-Public Patches betrays (ign...)Lack of Knowledge - Authored by: webster on Sunday, May 29 2005 @ 04:16 PM EDT
- SCO's Non-Public Patches - Authored by: 1N8 M4L1C3 on Sunday, May 29 2005 @ 04:49 PM EDT
- It's easy to tell that's not what SCO meant... - Authored by: greyhat on Sunday, May 29 2005 @ 06:21 PM EDT
- SCO's Non-Public Patches - THEORY NOT FEASIBLE - Authored by: Anonymous on Sunday, May 29 2005 @ 06:34 PM EDT
- Another possibility - Authored by: Anonymous on Sunday, May 29 2005 @ 08:08 PM EDT
- Are we not being rather narrow minded? - Authored by: Anonymous on Monday, May 30 2005 @ 08:10 AM EDT
- BS&F's Non-Public Patches - Authored by: tangomike on Monday, May 30 2005 @ 10:13 AM EDT
- Pointless & contrary to the claim and license - Authored by: Anonymous on Tuesday, May 31 2005 @ 01:26 PM EDT
| |
| Authored by: Anonymous on Sunday, May 29 2005 @ 03:59 PM EDT |
The problem may be one of semantics. You can't make a non-public
"contributions" to the Linux kernel. But you can make non-public
"changes" to the kernel.
The GPL does allow anyone to make non-public changes to any GPL-licensed
software, as long as the software is not distributed. Of course: if IBM wants
their contributions to be useful for their customers, then they need to publish
them. Out there in the open.
But nobody can prevent me from changing the Linux kernel for my own uses. It's
my right as a licensee and I don't have to tell anyone about it. If I later
distribute my work, then I have to make it public.
This is very different from the BSD license, where you can make changes to
software and then redistribute it and say it's your own, like Microsoft
alledgedly did with the BSD's TCP/IP stack.
However, it is possible for a company like IBM, for instance, to do internal
development in the Linux kernel and later on decide not to release such
software. For instance, IBM may decide, as an internal project, to port their
legendary WorkPlace Shell (the wonderful GUI for OS/2) to Linux and create some
hooks for it in the kernel.
If they later decide to kill the project, they do not have to make anything
public, and they don't have to publish the code, not even the modified Linux
kernel files that they may have developed for it. And yes, they are still
allowed to use the WorkPlace Shell for Linux in their own computers. As long as
it doesn't leave the licensee's internal offices, the GPL has no problem with
non-published contributions, because they aren't really
"contributions".
Now suppose IBM did make some internal kernel changes that would interest SCO,
even if IBM later decided not to release them. I think SCO has a point in asking
for such deceased projects' code. It may help them establish that IBM had
intentionally worked on something that they shouldn't have or that they've been
saying they haven't.
In short: non-public changes are possible, as long as the code is not later
released in binary or source formats.[ Reply to This | # ]
|
| |
| Authored by: Anonymous on Sunday, May 29 2005 @ 04:04 PM EDT |
Suppose Microsoft, or other companies opposed to any form of a successful Linux
kernel development in general, setup some proprietary code which could fit
within the Linux kernel, but before submitting it, embed it within their own
application, and in a future claim that the code was misused?
What part of the development process could avoid such issue? [ Reply to This | # ]
|
| |
| Authored by: Nick_UK on Sunday, May 29 2005 @ 05:06 PM EDT |
Also under the 'pyramid' like structure are the minions
(millions?)
wandering the desert (like me) that report
problems to the list - these
then get looked at.
A really good example is my post to the
LKML when I had
NIC problems after a kernel upgrade:
NIC
problems - a mail to LKML
If you read the thread all the
way through, it eventually
turns out a BIOS setting on my machine caused it
- but a
Kernel dev (OGAWA Hirofumi) spent all that time with me
trying
to sort it. I doubt you will get better service
anywhere else.
Nick [ Reply to This | # ]
|
| |
| Authored by: Khym Chanur on Sunday, May 29 2005 @ 05:12 PM EDT |
How old is the "signed-off by" practice? I remember some new practice
being instituted because of the SCO fiasco, to make it easier to track down who
was involved with a particular piece of code. Was this it?
---
Give a man a match, and he'll be warm for a minute, but set him on fire, and
he'll be warm for the rest of his life. (Paraphrased from Terry Pratchett)[ Reply to This | # ]
|
| |
| Authored by: dscho on Sunday, May 29 2005 @ 06:05 PM EDT |
while I was well aware of the process, as I studied it in order to become
a better developer (I write programs since 23 years), I have to shout out loud
"Thank you" to the time and the understanding of Greg and Andrew to
explain
the process so clearly to laymen.
People often do not realize how difficult their field of expertise is to
understand for other people, who did not happen to study that particular
field. That is the case for American Law, which at times seems very strange,
difficult and injust to me. That is why I also thank PJ for explaining it
so well.
Long live Open Source (not only the computer kind, but in every space of life,
like PJ has shown us!)
Dscho
[ Reply to This | # ]
|
| |
| Authored by: Tufty on Sunday, May 29 2005 @ 06:59 PM EDT |
Fascinating. May I suggest that a representative from each of Microsoft, IBM and
SCO submit a similar account of how they process things. It would be very
interesting to see how a comercial company handles these things. No trade
secrets just the overall process. How do things get tested and controlled in
Longhorn for example?
---
There has to be a rabbit down this rabbit hole somewhere!
Now I want it's hide.[ Reply to This | # ]
|
| |
| Authored by: Anonymous on Sunday, May 29 2005 @ 07:18 PM EDT |
Interesting article. But it describes the _current_ patch submission procedure,
which was only introduced _after_ this whole SCO mess started. Patch submission
before March 2003 was much more chaotic.
[ Reply to This | # ]
|
| |
| Authored by: Anonymous on Monday, May 30 2005 @ 12:42 AM EDT |
I think that generally when people complain about this is because there is not a
single source of easy feature digests for the mass consumers. There are a miriad
of websites and forums where the current and upcomming kernel features and
improvements are discussed but there is just not a match with the PR and
marketing campaigns of companies like Microsoft.
Maybe it would be helpful if in parallel with the linux-kernel list there would
be a similar information channel where the top layers of the pyramid announce
what they are working on (in very leyman terms of course). This channel should
be kept as the reference for PR much in the same way that linux-kernel is the
reference for development.
[ Reply to This | # ]
|
| |
| Authored by: Anonymous on Monday, May 30 2005 @ 01:04 AM EDT |
" Comments are very good to have, but they have to be good comments.
Bad comments explain how the code works, who wrote a specific function on a
specific date, or other such useless things.
Good comments explain what the file or function does, and why it does it."
That was in 2002.
Are bad comments also a useless thing for the purpose of the DCO?
[ Reply to This | # ]
|
| |
| Authored by: tredman on Monday, May 30 2005 @ 01:26 AM EDT |
I had a chance to browse through his personal web page, and he really does have
some very interesting things to say, from a programmer's point of view, anyway.
I wasn't aware he had as much of a full plate as he does. I only really knew
him as the USB subsystem maintainer. He certainly knows his way around the
kernel, and that tends to explain why his name pops up as much as Linus
Torvalds, Alan Cox, Andrew Morton, and many others.
One thing that did catch my eye was a comment he made about Bitkeeper, and how
there was so much going on behind the scenes that people just didn't know about.
I'd love to sit and pick his brain about that one day. I'm sure it makes for
some enlightening telling.
---
Tim
"I drank what?" - Socrates, 399 BCE[ Reply to This | # ]
|
| |
| Authored by: geoff lane on Monday, May 30 2005 @ 03:01 AM EDT |
| Sometimes a huge linux kernel patch is submitted that touches on many components
and subsystems. These are always rejected because it is impossible (or
impractical) to determine the full concequences of applying the patch.
The
EU is attempting to apply a huge patch (200 pages) to the existing EU
constitution and while it has been approved by the maintainers, it has been
rejected by the users.
For the Linux kernel the solution is to break the
huge patch into many smaller patches and get each applied seperately. This
produces a controlled change where at each stage there is still a stable
kernel.
If the EU wants to change, they have to take the same approach; many
small changes made seperately. It may take longer but the end result is much
more likely to work.
---
I'm not a Windows user, consequently I'm
not
afraid of receiving email from total strangers.
[ Reply to This | # ]
|
| |
| Authored by: Anonymous on Monday, May 30 2005 @ 06:21 AM EDT |
Signed-off-by: was only mooted in May 2004. SCO's issues (if any) are from
well before that. So it's slightly disingenuous to just enumerate the current
process without even mentioning that it's changed since, and partly in response
to, SCO's lawsuits.
http://kerneltrap.org/node/3929 [ Reply to This | # ]
|
| |
| Authored by: gumnos on Monday, May 30 2005 @ 09:09 AM EDT |
While there (now*) seem to be a considerably rigorous gauntlet
each patch must run to make it into an official kernel, one might still find
objections that once the kernel source makes it to a distributor (RH, Suse,
Debian, Joe's Linux Distro, etc) the process can break down. Any distributor
can modify a pristine codebase and introduce unvetted patches that they then
distribute.
However, this then becomes an issue of "how much do you
trust your distributor to maintain the chain of trust?".
With
big-names such as RH, Suse, Debian,
ConnectMandrakeiva, TurboLinux, etc, it's one
thing. For some, like Linux From Scratch and Gentoo [insert a
little cheering from the LFS/Gentoo crowds], you get the source yourself and can
compare/rsync with the original. However, when you start getting into
the smaller players, there's not so much riding on their reputation, or there's
little way to confirm that the source they used didn't introduce some small bug.
I suppose one could download the source they make available, attempt to compile
it with the same version of the compilier with the same versions of all the
library files, and then do a binary diff on the resulting binary with the
original distributed binary. However, that's a whole lot of work for small-name
distros.
To be a step ahead, one would have to download the vetted
source from each crew (kernel, GNU, KDE, etc) and build it yourself. At least
with Linux/*BSD, you can do that.
Ah, well...just my early
morning ramblings...beware of |-|4x0r3d Linux distros
:-P
-gumnos
*as others have
mentioned, this signed-off-by process has not been around for the whole
history of the kernel. Additionally, such sign-off is likely not implemented in
every other project either. Gimp? OO.o? KDE? Gnome? Ethereal? XMMS?
Mozilla? Apache? MySQL? xbill? etc... Some do, some may not. It only
takes one weak link in the chain to allow remote folks to run code on your
machine.
[ Reply to This | # ]
|
| |
| Authored by: Anonymous on Monday, May 30 2005 @ 09:09 AM EDT |
1) Changing their name to "The SCO Group".
2) "Forgetting" how Linux is developed.
3) Wanting blakmail money for use of Linux.
I would not call them "confused" at all.
Lying is more like it.
[ Reply to This | # ]
|
| |
| Authored by: Anonymous on Tuesday, May 31 2005 @ 01:23 PM EDT |
and being IBM probably has a 200 page process document and
multiple levels of review and approval before anything
gets sent to a kernel mailing list. IBM knows exactly what
it did and did not put in the Linux kernel, and IBM's
lawyers certainly check everything at least twice. This
means the anything IBM submitted to Linux was legitimate,
except in the SCOverse. [ Reply to This | # ]
|
|
|
|
|




